Openchain - Umfrage zu Open Source
Openchain - Umfrage zur Opensource Nutzung
Die Openchain Workgroup der Linux Foundation, die in den letzten Jahren vor allem den Standard ISO 5230 – Open Source Compliance geprägt hat, hat ein Umfrage über den Einsatz und Umgang von Open Source in Unternehmen erarbeitet. Als internationale Erhebung soll sie helfen die Arbeit der Organisation zu fokussieren und den teilnehmenden Unternehmen eine Möglichkeit geben, sich selbst in Bezug auf Open Source zu reflektieren. Die Ergebnisse der Umfrage werden unter Creative Commons zero (CC-0) lizenzesiert und lassen sich somit frei verwenden.
Als Unterstützer der Openchain Initiative rufen wir unsere Kunden und Partner auf, die Umfrage zu unterstützen und damit den Pool an Informationen anzureichern. Die Umfrage erfordert ca. 10 Minuten Zeit und kann unter diesem Link erreicht werden.


Open Source Compliance im Kontext von CI/CD
In den letzte Jahren hat sich Continuous Integration und Deployment (CI/CD)- die ständige Integration von Änderungen, deren automatisiertes Testen und Ausbringen – als Best Practise etabliert. Die gesteigerte Qualität und die Produktivitätsverbesserungen, die sich hierdurch erzielen lassen, sind enorm und sollten daher von jedem Entwicklungsteam angestrebt werden. Gleichzeitig wächst jedoch auch die Herausforderung im Bereich Open Source eine solide Dokumentation und rechtliche Compliance herzustellen.
Durch das kontinuierlich neue Bauen von Lösungen kann sich auch kontinuierlich die Zusammensetzung der Lösung ändern. Da der Anteil an Dritt-Software (OpenSource-Komponenten) stetig zunimmt, wird mit dem neuen Bau auch die Wahrscheinlichkeit größer, dass sich die Zusammensetzung der automatisch hinzugezogenen Dritt-Software ändert. Das Upgrade der Komponente X von Version 1.5.7 auf 1.5.8 kann bereits neue Lizenzverpflichtungen auslösen.
Leider kann eine strikte Versionskontrolle alleine diese Problematik nicht auflösen, da immer wieder das Schließen von identifizierten Schwachstellen (Vulnerabilities) und anderen Fehlerbehebungen Versions-Upgrades in allen Ebenen erforderlich machen wird. Daher stellt sich die Frage, wie sich die Compliance (1) auch in diesem dynamischen Kontext sicherstellen lässt.
Branching-Konzept als Lösungsbaustein
Um diese Frage zu beantworten, ist es erforderlich, sich zunächst mit dem Prozedere des Entwicklungsteams vertraut zu machen. Leider lässt sich immer wieder feststellen, dass es keine generell einheitlich definierte Vorgehensweise gibt. Dabei ist die Branching-Strategie des Entwicklungsteams essentiell für den richtigen Ansatzpunkt einer Open Source Compliance.
Mit Git-Flow (2), Github-Flow (3) und Gitlab-Flow (4) stehen drei anerkannte, aber zunächst unterschiedlich anmutende Handlungsanweisungen zur Verfügung. Die Varianten unterscheiden sich jedoch weniger, als es auf den ersten Blick erscheint.
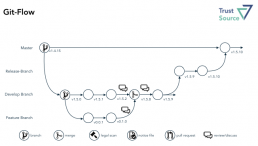
Im Git-Flow bleibt der Master unantastbar die Version, die sich auch im Produktivsystem findet. Hierdurch verspricht man sich, ein einfaches Rollback auf eine ältere Version, sollte das Deployment 2 PROD einer neuen Version fehlschlagen. Ausgehend von dem Develop-Branch werden einzelne Feature-Branches erzeugt und jeweils wieder auf den Develop-Branch zusammengeführt, um das parallele Entwickeln durch mehrere „Feature“-Teams an dem Develop-Objekt zuzulassen. Atlassian ergänzt in der Beschreibung zudem noch den Umgang mit Hot-Fixes und Releases.
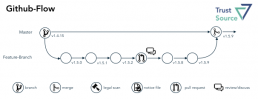
Wesentlich einfacher erscheint der Github-Flow. Einen Teil der Vereinfachung erfährt das Modell jedoch aufgrund der Verlagerung des Masters auf die Rolle des (im Git-Flow) Develop-Branch. Das vereinfacht das Verständnis, da die meisten Werkzeuge #master als Default-Branch verwenden und somit der Entwickler im Default auf dem richtigen Branch arbeitet. Unbeantwortet bleiben im GitHub-Flow jedoch die Fragen nach dem Merge in umfangreicheren Projekten, die sich aus mehreren Modulen zusammensetzen. Damit ist man dann schnell wieder bei einem Release-Branch, wie ihn der Git-Flow kennt.
GitLab hat dies in seiner Flow-Darstellung noch einmal aufgegriffen und explizite Umgebungs-Branches eingeführt, bspw. PROD, PRE-PROD, die solche umgebungspezifischen Assemblies abbilden. Die Bedeutung solcher Varianten sollte jedoch dank dynamischer, bzw umgebungsspezifischer Container-Konfiguration sukzessive abnehmen.
Inwiefern sich das als geeignet erweist, mag nur der jeweilige Projektkontext bewerten. Aus unserer Erfahrung ist ein Failback im Kontext eines Zero-Downtime-Deployments eher weniger ein Thema, das irgendwelche Repositories betrifft. Man würde für ein Rollback sicher auch nicht auf das Soruce-Repository zurückgreifen wollen, sondern lieber die bereits gefertigten Artefakte aus einem Binary-Repository holen. Daher empfehlen wir den Verzicht auf den Git-Flow-„Master“ zugunsten eines „DEV-Masters“ im Sinne des GitHub-Flows.
Die Entscheidung, ob man noch unterschiedliche „Release“-Versionen aufhebt, ergibt sich dann aus der Deployment-Philosophie bzw. dem Geschäftsszenario. Im SaaS-Kontext ist die Dringlichkeit für Release-Branches eher geringer. Wird Software hingegen verteilt, bspw. auf Geräte, die nicht beliebig für Updates zur Verfügung stehen, ist das ein essentieller Schritt für die nachhaltige Wartung. Auf jeden Fall empfehlen wir unabhängig vom gewählten Flow eindringlich die Nutzung von Binary-Repositories, um das ewige Neubauen der Artefakte nach erfolgreichem Test und Dokumentation weitgehend zu unterbinden.
Unabhängig vom gewählten Flow emfpehlen wir stets die Nutzung von Binary-Repositories
Umgang mit Multi-Modul-Projekten
Unbeleuchtet bei all diesen Themen bleibt die Frage nach den „Multi-Modul-Projekten“. Zwar werden diese durch Modularisierungstrends wie Micro-Service-Architekturen mit der Zeit weniger werden, jedoch lässt sich nicht alles endlos teilen und nicht alle Commons lassen sich stets auflösen.
Die Frage nach der richtigen Granularität des Repository-Schnitts wird fall-, bzw. projektspezifische zu beantworten sein. Daher wird es um so wichtiger, auf Seiten der Composistion Analysis ein System zu haben, das hier vollkommene Flexibilität bietet. Wir haben TrustSource daher so konzipiert, dass es beliebige Granularitäten unterstützt. Dazu kennt es die Konstrukte „Projekt“, „Modul“ und „Komponente“.
Die Idee des Projektes ist es, ein Entwicklungsvorhaben zu klammern. Es bildet den Container, in den alles projektspezifische reinkommt: Rahmenbedingungen, allgemeine Berechtigungen, alle zugehörigen Artefakte, Infrastrukturelemente etc.
Das TrustSource-Projekt ist nur eine Klammer für eine Menge an Delivery-Artefakten.
Die Module bilden entweder einzelne Deployment- oder Build-Artefakte. Dabei kann ein Modul entweder das Ergebnis eines Builds oder eine eigenständige Drittkomponente sein. Als Build versteht sich in dem Kontext alles, was im Zuge der Eigenentwicklung gebaut wird. Das kann wiederum ein einzelnes Artefakt oder ein Multi-Komponenten Projekt (bspw. EAR) sein.
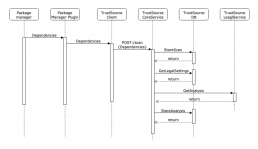
Die einzelnen Komponenten, die — auch transitiv — zum Bauen eines Moduls angezogen werden, löst der der Scanner während des Bauens auf und überträgt die Stückliste an TrustSource (s. nebenstehende Grafik). Dabei kann das /SCAN-API, welches die Information entgegennimmt, auch Informationen zu „Branch“ und „Tag“ aufnehmen. Dies hilft später, die Eingaben wiederzufinden.
Zudem unterstützt TrustSource die Verwaltung von Drittprodukten. Das können Komponenten sein, die nicht beim Bauen auftauchen, wie ein MySQL- oder JBoss-Server, eine Bild-Datei (Ressourcen) oder eine gekaufte Library. Diese lassen sich über die Mechanismen Infrastruktur Management (für Open Source-Komponenten) oder COTS-Management (für kommerzielle 3rd Party) verwalten und organisieren und einem Projekt manuell als eigenständige Module hinzufügen.
Das Modul ist also die Klammer der Informationen für ein Build-Artefakt. Es enthält den Teil der rechtlichen Informationen, die modulspezifisch sind, die Architekturposition, Zugriffsrechte etc.. Soweit Letztere nicht für das jeweilige Modul explizit geändert werden, sind sie bereits durch das übergeordnete Projekt gesetzt.
Beispiel
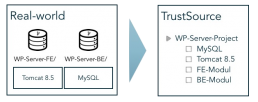
Nachstehendes Bild zeigt die Struktur eines Workplace-Servers. Dieser besteht aus einem Frontend- und einem Backend-Modul, die beide in einem Projekt-Repository abgelegt sind. Der Workplace-Server benötigt zudem einen Tomcat 8.5 und einen MySQL-Server als Ausführungsinfrastruktur. Diese beiden Module sind als Infrastruktur-Module hinzugefügt. Sie werden nicht gebaut, sind aber Bestandteil der Anwendung und entsprechend in die Compliance-Betrachtung einzubeziehen.
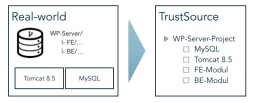
Dabei ist es egal, ob die Frontend und Backend-Module aus dem gleichen Repository kommen oder aus unterschiedlichen. Das Ergebnis in TrustSource sieht unverändert aus.
Interessant wird jetzt die Release-Strategie. Liegt die Release-Version auf Anwendungs-Ebene (äußeres Kästchen), wird es also immer nur eine Version der Anwendung geben, sind alle Module jeweils nachzuziehen, um mit der Release-Version Schritt zu halten, oder es muss eine Kombination unterschiedlicher Sub-Release zu dem Gesamt-Release geben. Zum Beispiel würde sich die Version 2.0.0 der Anwendung aus den Versionen Tomcat 8.5, MySQL 5.1 und Frontend 2.0.5 sowie Backend 1.5.16 konstituieren.
Für diesen Fall gibt es seitens des Repository nur dann eine Entsprechung, wenn ein GitLab-artiges Repository für die Produktionsumgebung gepflegt wird, in welches die unterschiedlichen Stände eingebracht werden. Es wird in diesem Kontext erforderlich – wie in allen Multi-Komponenten-on-premises-Projekten ohnehin – einen Release-Brach aufzusetzen, um das Zusammenspiel von Frontend und Backend zu testen, bevor sie ausgebracht werden.
Einbindung der Compliance in den CI/CD-Flow
Als Scan wird das Ergebnis des Scanners bezeichnet, welcher lokal oder auf dem Build-Server ausgeführt wird. Er erzeugt die Struktur inklusive Abhängigkeiten und überträgt diesen „Scan“ mit Hilfe des gleichnamigen API an TrustSource. Dort übernimmt der Scan-Processor den Scan, gleicht die gefundenen Informationen mit der internen Komponentendatenbank ab und bindet den Input an das zugehörige Modul.
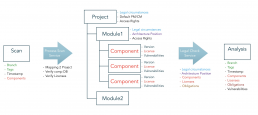
Hierdurch entsteht der Kontext. Das Projekt und das Modul halten Rahmenbedingungen, welche für das Projekt bzw. Modul gelten sollen. Das betrifft die Kommerzialisierung sowie andere relevante Aspekte, wie bspw. den Schutzbedarf von IP. Diese Information zusammen mit den Komponenten und Lizenz-Informationen werden dann an den Legal-Check-Service übergeben, welcher die sich aus den Rahmenbedingungen und den Lizenzen ergebenden Verpflichtungen (Obligations) ableitet.
In der Detail-Ansicht findet der Benutzer letztendlich die Summe aller dieser Schritte, das Analyse-Ergebnis. Um eine engere Bindung zwischen dem Quellcode und der Management-Welt herzustellen, stellt TrustSource die Felder „branch“ und „tag“ in dem API /SCAN bereit. Somit lassen sich mehrere Zustände eines Moduls problemlos auseinanderhalten.

Wichtig für das Verständnis der weiteren Schritte ist es, zu verstehen, dass der SCAN die Struktur des Quellcodes wiedergibt. Dieser ist zunächst unbewertet. Erst das in der Detail-Ansicht dargestellte Analyse-Ergebnis ist eine Interpretation vor dem Hintergrund der zum Analysezeitpunkt gültigen Rahmenbedingungen! Daher gilt:
- Jeder Upload erzeugt einen neuen SCAN
- Ein SCAN wird in der Regel einem MODUL zugeordnet, wodurch er seine Rahmeninformationen erhält
- Jedes MODUL gehört zu genau einem PROJEKT – bis auf das systemeigene Sammelmodul „Unassigned“, hier findet sich alles, was nicht automatisch zugeordnet werden kann
- Jeder SCAN erzeugt mindestens ein ANALYSEERGEBNIS (automatisiert)
- Ein MODUL kann beliebig viele ANALYSEERGEBNISSE haben
- Ein SCAN kann beliebig oft an TrustSource übertragen werden, die Zuordnung zu einem MODUL lässt sich bei der Übertragung festlegen
Scans zuordnen
Aus dieser Menge an Fakten lassen sich beliebige Szenarien zusammenstellen. So kann jeder Entwickler an das Ziel-Modul seine Scans schicken und diese mit Hilfe von Branches und Tags differenzieren. Um eine direkte Zuordnung zwischen Code und Analyse-Information herzustellen, könnte man die Commit-ID als Tag anlegen.
Will ein Entwickler seine Experimente nicht in dem allgemeinen und für das gesamte Projekt ersichtlichen Modul einbringen, kann er eine eigene Projekt/Modul-Konstellation anlegen und die rechtlichen Einstellungen aus dem ursprünglichen Projekt kopieren. Somit kann er in seiner Version herumprobieren, ohne den allgemeinen Stack zu belasten.
Andererseits kann es auch sinnvoll sein, sämtliche Branches in dem Modul zu halten, um einen guten Überblick über die Veränderungen zu erhalten. Mit Hilfe des Branch-Selektors im User-Interface lässt sich jede Version direkt auswählen und einsehen.
Approvals einordnen
Doch was ist nun ein Approval? Das Approval ist ein administrativer Schritt, der es dem Projektleiter und den Entwicklern ermöglichen soll, sich von der Domänen-fremden Aufgabe der rechtlichen Begutachtung ihrer Leistung frei zu zeichnen. Hierzu bereitet TrustSource alle Unterlagen für eine Prüfung auf und stellt diese einem rechtlich gebildeten – im TrustSource-Sprech, dem Compliance Manager – zur Verfügung. Dieser muss dann nur noch die Vollständigkeit bzw. Eignung prüfen, wobei ihn TrustSource auch unterstützt, und kann dann eine Freigabe erteilen.
Die Approvals finden idealerweise nicht nach jedem Scan statt, sondern nur vor Merge-Schritten. Dabei sind der Umfang und die Häufigkeit organisationsspezifisch festzulegen. Im Regelfall erfolgt ein Merge in einem vergleichbaren Kontext wie in nachstehender Abbildung gezeigt. Dabei ist es unerheblich, ob es sich um einen Pull-request oder einen richtigen Merge handelt. Ist der zu integrierende Inhalt von einem für seinen Umfang vollständigen Notice-File versehen, kann dieser Inhalt auch in den zusammengeführten Baum übernommen werden und hält die Gesamtdokumentation somit vollständig.
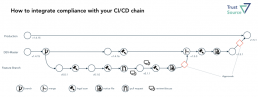
Die obige Darstellung ist um die Scans und die Generierung der Notice Files erweitert. Wir empfehlen, die Notice-Files als Bestandteil einer Definition of Done aufzunehmen. TrustSource verfügt über einen Notice-File Generator. Dieser sammelt sämtliche vorhandenen Informationen und zeigt, welche Informationen noch fehlen, um den Notice-File zu vervollständigen.
Wir empfehlen, vor jedem Merge einen Notice-File zu erzeugen. So ist jeweils nur das Delta zum bisherigen Bestand zu ergänzen
Alle ergänzten Daten stehen ab dem Zeitpunkt der Ergänzung allen Projekten zur Verfügung. Somit sind allgemeine Informationen nur einmal zu erfassen. Das reduziert die Clearing-Aufwände erheblich
Die tatsächliche Gestaltung der Abläufe wird in jedem Unternehmen, vermutlich sogar in jedem Projekt, etwas anders verlaufen. Eine allgemeingültige Darstellung zu verordnen, ist daher weder sinnvoll, noch empfehlenswert. Die Wahrscheinlichkeit, dass sie mehr schadet als nutzt, ist einfach zu hoch. Auch kann es sinnvoll sein, das Vorgehen im Zeitablauf anzupassen. Wird ein Modul nur noch angepasst, ist ein weniger differenziertes Vorgehen empfehlenswert, als wenn mehrere Teams gleichzeitig an den Elementen arbeiten. Wird jedoch vor jedem Merge ein Notice-File erzeugt, ist jeweils nur as Delta zum bereits bestehenden Notice-File zu ergänzen und sowohl der Arbeitsaufwand als auch die spätere Herausforderung für die Compliance-Prüfung halten sich in Grenzen.
Literaturhinweise:
(1) Welche Herausforderungen die Compliance beantworten muss, findet sich in dem Artikel „Aktuelle Herausforderungen der Open Source Compliance“.
(2) Git-Flow: https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
(3) GitHub-Flow: https://guides.github.com/introduction/flow/
(4) GitLab-Flow: https://about.gitlab.com/2014/09/29/gitlab-flow/
(5) s. https://github.com/dotnet/corefx/
TrustSource mit Vulnerability Lake (beta)
Vulnerability Lake ergänzt das TrustSource Angebot
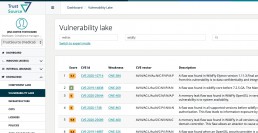
Aufgrund vieler Anfragen haben wir uns entschlossen, unsere interne Schwachstellen-DB für unsere Kunden zu öffnen. Ab der Version 2.0 wird TrustSource seine interne „Known Vulnerability“-Datenbank für die Suche zur Verfügung stellen. Es werden mehrere Suchmöglichkeiten zur Verfügung stehen:
- TrustSource Vulnerability-Lake öffentliches Web-UI
eine öffentliche, kostenlose Suche über unsere Schwachstellendaten für die manuelle Nutzung. Zudem wird es möglich sein, sich für bis zu fünf Produkte zu registrieren, um Updates direkt in den eigenen Posteingang zu erhalten. - TrustSource Vulnerability-Lake Web-UI
eine in die TrustSource-Lösung integrierte Such-UI für unsere registrierten Benutzer - TrustSource Vulnerability-Lake API
eine API, die die Such- und Abgleichsfunktionen auch für die programmatische Nutzung bereitstellt. Eine bestimmte Anzahl von Transaktionen pro Monat wird kostenlos sein. Die API wird auch einige statistische Informationen zur besseren Interpretation der Schwachstellendaten bereitstellen.
Die öffentliche Web-Benutzeroberfläche sowie die in TrustSource integrierte Web-Benutzeroberfläche werden einen einfachen und einen Experten-Suchmodus bieten. Im einfachen Modus können Sie eine Produktinformation angeben und die Suche nach Organisation oder Version erweitern. In der professionellen Version kann dies in einem einzigen String kodiert werden, z.B. ’some-org:my-product:3.2.1′ Die Ergebnisse enthalten die typischen Informationen wie CVSS Base Score, CVE-ID, Beschreibung und weiterführende Links.
Die Daten werden alle zwei Stunden aktualisiert. Im ersten Anlauf wird die Lösung nur NVD-Daten enthalten. Später werden wir den Umfang dort erweitern, wo es sinnvoll ist. In den letzten Jahren haben wir eine steigende Verbreitung von CNAs – den Stellen, die CVEs vergeben – beobachtet. Das reduziert die Dringlichkeit, viele verschiedene Quellen zu verarbeiten. Abhängig von Ihrem Anwendungsfall kann es aber dennoch sinnvoll sein, weitere Quellen einzubeziehen. Zögern Sie daher nicht, uns zu kontaktieren, wenn Sie eine wichtige Quelle hingefügt haben möchten.

Wie TrustSource vor Dependency Konfusion schützen kann
Was ist passiert?
Sicherheitsforscher haben es mit Hilfe eines Dependency-Konfusion Angriffes geschafft, sich Zugang zu diversen Hochsicherheits-Netzwerken zu verschaffen. Mit Hilfe dieses Angriffes ist es Ihnen gelungen, Informationen und Daten aus den betroffenen Netzwerken nach draußen zu schicken. Je nach Ausgestaltung des Angriffsszenarios wären jedoch auch andere Aktivitäten denkbar. Erst einmal hinter den Verteidigungslinien angekommen, lässt sich das Schadensszenario frei wählen.
Wie ist der Angriff erfolgt?
Die Sicherheitsforscher sind auf die Idee gekommen, als Sie in den veröffentlichten Open Source Werkzeugen der Firmen (Apple, Adobe, etc.) Namen privater Pakete gefunden haben.
Oft nutzen Unternehmen Open source und ergänzen gewisse Funktionalitäten oder grafische Steuerelemente mit eigenen Bibliotheken. Diese wiederum werden nur von einem Team entwickelt und als eigene Pakete bzw. Bibliotheken für andere Entwicklungsteams bereitgestellt. Das ist effizient und komfortabel, da die breite Menge der Entwicklungs-Teams sich nicht kümmern muss, das Look-and-Feel dennoch konsistent über unterschiedliche Anwendungen bzw. Services bleibt.
Spielen die Unternehmen nun Software zurück an die Community und werden die Referenzen auf solche „privaten“ Pakete nicht aus dem Quellcode entfernt, trägt die Veröffentlichung dien Namen dieser Pakete nach draußen. Das an sich ist noch nicht so gefährlich. Interessant wird dies erst, wenn die Information für eine Dependency-Attack (s. nebenan) ausgenutzt wird.
Wie können Sie sich schützen?
- Komponenten-Namen:
Folgen die internen Komponentennamen einem Namens-Schema, wie bspw.ORG.COPMANY.UNIT.UITOOLSwird es für Dritte erheblich schwieriger entsprechende Namen in den Paketmanagern anzulegen, ohne dass es Aufsehen erregt.ORG.COPMANY.UNIT.UITOOLSfällt mehr auf, als die 100ste Version vonUITOOLS. - Nutzung von Paketmanager-Proxies:
Um in dem Angriff erfolgreich zu sein, sind die lokalen Verteilmechanismen zu überlisten. Es sollte sichergestellt sein, dass für gewisse Paket-Typen, u.a. bspw. mit Hilfe der Namenskennung ode reiner einfachen Blacklist, keine Updates von außen gezogen werden. - Versionsüberwachung:
Mit Hilfe einer Versionshistorie wird es schnell möglich, festzustellen, welche Versionen im Einsatz sind. Ein Sprung von 1.2.3 zu 69.1.0 lässt sich schnell entdecken, bzw. fällt auf.
Was ist eine Dependency-Konfusion?
Moderne Package-Systeme nutzen Paketmanager, insbesondere um die stetig wachsende Zahl von Open Source Komponenten zu verwalten. Jede Build-Vorschrift enthält daher eine Liste der einzubindenden Komponenten. Unter Java ist das die POM.XML-Datei, bei Node.JS (JavaScript) ist das die PACKAGES.JSON.
In dieser Datei sind die Komponenten und die Mindestanforderungen and die Komponenten, die Versionsnummern angegeben. Da sich viele Komponenten öfter ändern, steht in den Vorschriften oft nicht nur die exakte Versionsangabe, bspw. 1.2.3 sondern ein Vermerk wie ^1.2.3, was so viel bedeutet wie: „Gib mir mindestens die 1.2.3 oder neuer.“ . Erfolgt seitens der Maintainer der Komponente eine Update auf bspw. 1.2.4 (neuer Patch) oder 1.3.0 (neues Feature) würde die eigene Lösung mit Hilfe der Formulierung beim nächsten Bauen von den Neuerungen profitieren können.
Wird nun in einem Package Manager von einem bösartigen Akteur eine neuere Version eingestellt, bspw. eine 2.1.0, so kann er relativ sicher sein, dass diese Version vom Package Management für den oben beschriebenen Kontext bereitgestellt würde. Baut das Projekt nun anständig, würde dieser schadhafte Code in ein QS-System ausgebracht und dort ausgeführt. Je nach
Sie wollen Schwachstellen entlang des gesamten Produkt-Lebenszyklus Ihres Produkt verlässlich überwachen?
TrustSource kann gegen solche Angriffe schützen!
TrustSource kennt die aktuellen Versionen Ihrer Module und Lösungen sowie der öffentlich verfügbaren. plötzliche Versionssprünge öffentlich verfügbarer Komponenten werden von unseren Systemen erkannt und an unser Support-Team zur Prüfung gemeldet. Kritisch einzustufende Entwicklungen werden an die Projekte zurückgemeldet.
Nutzen Sie bereits TrustSource ist Ihnen vermutlich das Konzept des „linked Modules“, des Einbindens von Releases eigener Software bekannt. Tauchen hier Versionen auf, die bisher unbekannt sind, führt auch dies zu einer Meldung an den jeweiligen Projektleiter. Somit können Sie sicher sein, entsprechende Entwicklungen schnell zu bemerken.
DeepScan - Effektive Lizenzen einfach identifizieren
TrustSource DeepScan - CLI, web-basiert oder als Teil von TrustSource
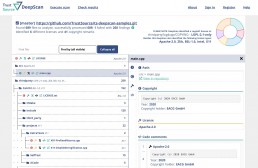
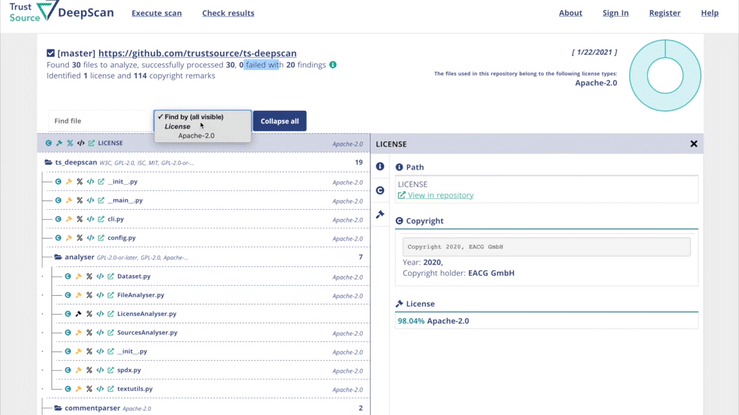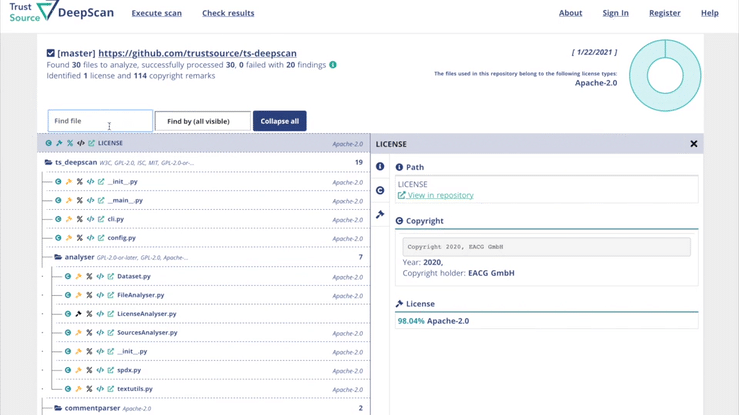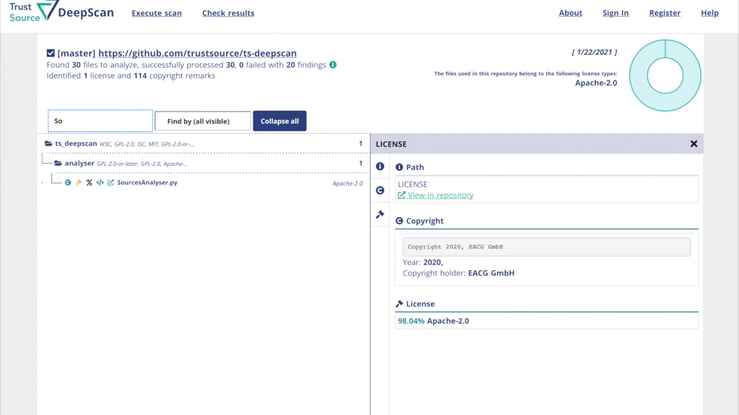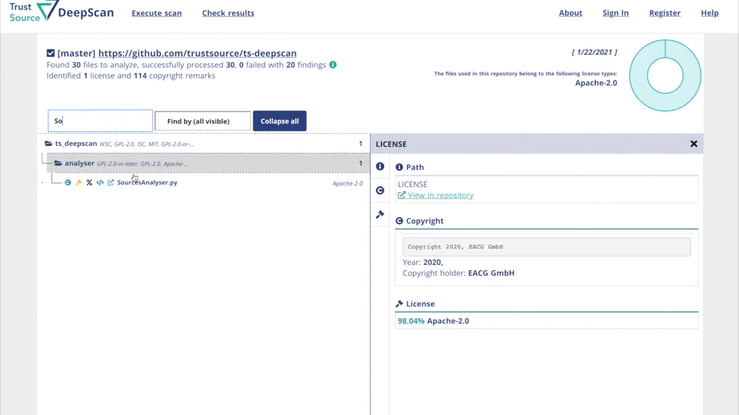
DeepScan – effektive Lizenzen einfach identifizieren: DeepScan ist ein Open-Source-Tool, das Ihnen hilft, Open Source Compliance zu erzeugen. Sie können DeepScan verwenden, um die Repositories Ihrer Lösung oder der Komponenten, die Sie anwenden, zu scannen. Es wird alle Lizenz- und – falls gewünscht – Copyright-Informationen identifizieren. Dies ist relevant, um sicherzustellen, dass Sie die Rechte und Pflichten, die mit den von Ihnen verwendeten Open-Source-Komponenten verbunden sind, hinreichend erfüllen können.
DeepScan ist in drei Geschmacksrichtungen verfügbar:
Die CLI-Version ist zwar voll funktionsfähig, erfordert aber, dass der Benutzer die Ergebnisdatei selbst auswertet. Die CLI-Version kann ihre Ergebnisse entweder via Standardausgabe oder in einer Datei mit JSON veröffentlichen. Die webbasierte Benutzeroberfläche bietet eine komfortable Möglichkeit, die Ergebnisse zu betrachten und mit ihnen zu arbeiten. Die in TrustSource integrierte Lösung ermöglicht es Ihnen, die Befunde zu ändern und Ihre Daten mit anderen zu teilen.
Warum ist die effektive Lizenz so wichtig?
Jeder, der Software entwickelt, sollte aus zwei Gründen ein Verständnis für die Komponenten haben, die er für seine Lösung einsetzt:
- Rechtlicher Rahmen
- Sicherheit
Rechtlichen Rahmen kennen
Aus rechtlicher Sicht ist es wichtig zu verstehen, woraus Ihre Lösung besteht. Open Source bedeutet nicht, dass alles frei verfügbar ist. Freien Zugang alleine heißt nicht, dass man frei von Verpflichtungen ist. Oft sind Open-Source-Komponenten mit einer Lizenz versehen, die vom Anwender die Einhaltung bestimmter Verpflichtungen erfordert. In vielen Fällen ist das Nutzungsrecht an die Einhaltung dieser Pflichten gebunden, z.B. an die Nennung des Urhebers.
Auszug Apache 2.0
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices ...
Theoretisch kann jede Komponente ihre eigene Lizenz haben. In der Praxis zeigt sich, dass es ca. 400 Lizenzen und unzählige Derivate gibt, die die Nutzung von Open Source regeln. Manche sind mehr, manche sind weniger restriktiv. Wenn Sie sich jedoch nicht um die Rechte und Pflichten kümmern, die mit den von Ihnen verwendeten Komponenten verbunden sind, rutschen Sie schnell aus der Rechtskonformität. Im schlimmsten Fall können die Strafverfolgungsbehörden die Geschäftsleitung von Unternehmen, die solchen Risiken nicht wirksam vorbeugen, wegen gewerbsmäßigen Betrugs anklagen.
DeepScan hilft dabei, Repositories auf Lizenzindikationen zu untersuchen und alle Ergebnisse auf komfortable Art und Weise offenzulegen. Zusammengefasst in einem Ergebnis, mit Links in die Tiefe des Repositories, die eine schnelle Nachverfolgung und Überprüfung ermöglichen.
Probieren Sie es aus!
Keine Installation oder Registrierung erforderlich…
Wissen was drin ist, hilft die Sicherheit zu verbessern
Der zweite Grund, warum Sie die Komponenten in Ihrer Lösung besser kennen sollten, ist, um frühzeitig von Problemen zu erfahren, die mit solchen Komponenten verbunden sind. Wenn Sie die Strukturen Ihrer Lösung regelmäßig mit TrustSource scannen lassen, sind alle Versionen chronologisch verfügbar. TrustSource prüft NVD und andere Schwachstellen-Quellen auf Updates und vergleicht die eingehenden Daten mit den Informationen zu den Komponenten. Wenn Sie eine verwundbare Komponente verwenden – oder verwendet haben, erhalten Sie eine Benachrichtigung.
Dies verschafft Ihnen einen Vorteil gegenüber potentiellen Angreifern und sichert Ihre Entwicklung. Sie können Ihre Kunden, die noch verwundbare Versionen verwenden, sofort informieren und ihnen helfen, den Missbrauch der Schadstellen zu verhindern sowie mit der Arbeit an Fixes beginnen, bevor ihre Lösung attackiert wird.
Es gibt also viele Gründe, warum Sie wissen sollten, was sich in Ihrem Code befindet….
Um mehr über die verschiedenen DeepScan-Lösungen zu erfahren, die wir anbieten, sehen Sie sich dieses kurze Einführungsvideo an. Dieser Vortrag (englische Sprache) wird auf der FOSDEM 21 im Software Composition Analysis DevRoom gehalten.

ISO 5230 - Standard für Open Source Compliance verabschiedet
Am 14. Dezember 2020 hat die Internationale Standardisierungsorganisation (ISO) mit ISO 5230 den ersten Standard zur Open-Source-Compliance (OSC) veröffentlicht. Der Standard ist das Ergebnis mehrjähriger Arbeit einer Arbeitsgruppe der Linux Foundation. Experten für Open-Source-Compliance aus führenden Technologieunternehmen wie ARM, Siemens oder Toyota haben in vielen Arbeitstreffen einen einfachen, aber effizienten Ansatz geformt, um die Herausforderungen der Open-Source-Compliance zu adressieren.
Das folgende Video erklärt die Kernidee des OpenChain-Projekts. Es ist eine Aufzeichnung der 10-minütigen Einführung in das OpenChain-Projekt. Jan Thielscher hat diesen Vortrag am 6. Februar auf der diesjährigen FOSDEM gehalten. Darin stellt er die Anforderungen der Spezifikation und somit die Säulen der ISO 5230 vor (Vortrag in engl. Sprache).

ISO 5230 ist relevant für Ihr Unternehmen? Sie wollen mehr erfahren?
Zögern Sie nicht, uns für ein unverbindliches Gespräch zu kontaktieren!
OpenChain zielt darauf ab, Vertrauen entlang der Wertschöpfungskette aufzubauen. Zertifizierte Teilnehmer erfüllen Anforderungen im Umgang und der Verwendung von Open Source, die es einfach machen, sich auf die Ergebnisse zu verlassen. Wir unterstützen die Arbeit mit und an OpenChain bereits seit mehreren Jahren, und haben wesentliche Aspekte einer organisationalen Verankerung der Compliance-Idee in TrustSource eingebettet. Damit ist TrustSource bestens geeignet, sowohl die Einführung als auch die laufende Einhaltung der ISO 5230 bzw. der OpenChain-Anforderungen zu unterstützen.
Lernen Sie, mit welchen Eigenschaften TrustSource Ihre OpenChain/ISO5230 Zertifizierung unterstützen kann
TrustSource @ FOSDEM 2021
TrustSource @ FOSDEM 2021
wir freuen uns auf die Vorträge von @Jan Thielscher & @Grigory Markin auf der FOSDEM 2021.
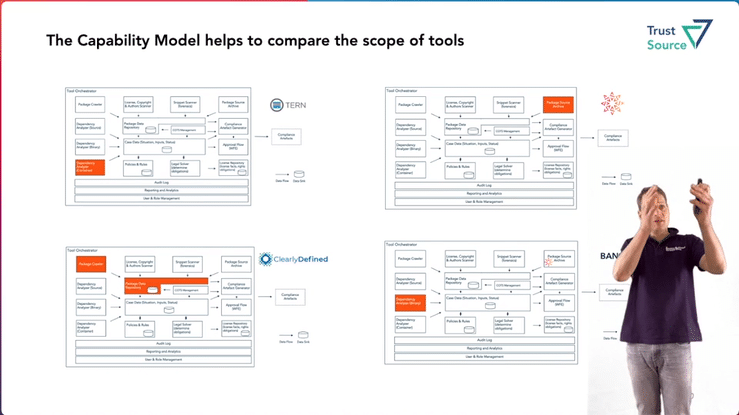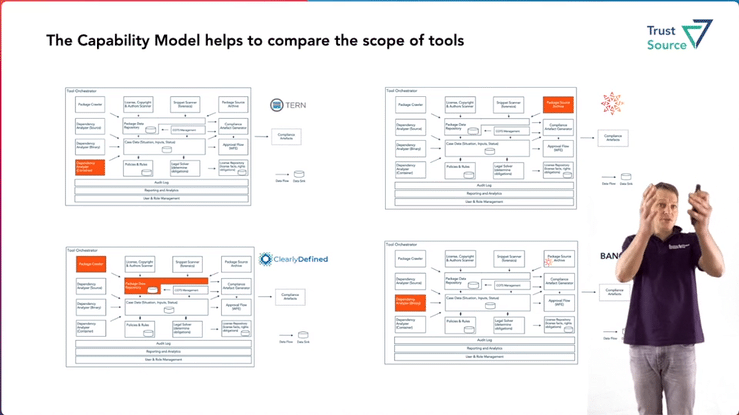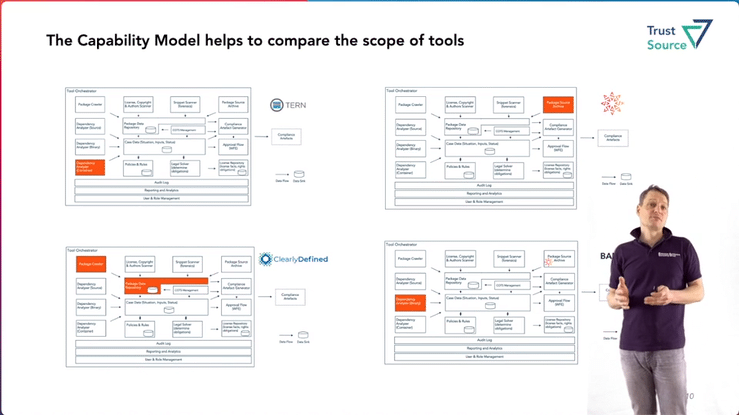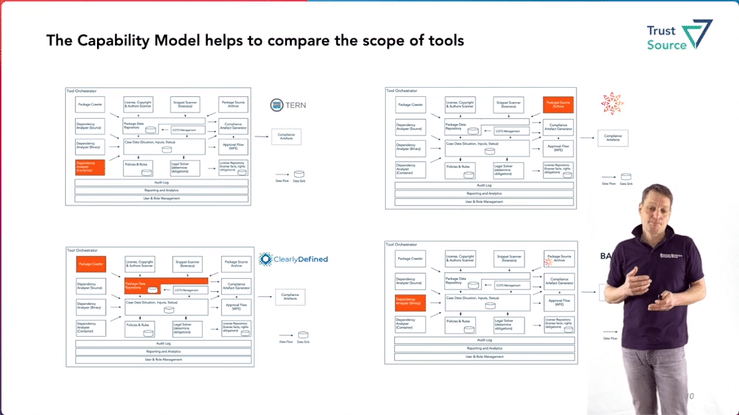
Open Source Compliance Tooling – Capability Reference Architecture
Jan wird im OpenChain Dev-Room das Referenzmodell der Open Source Tooling Workgroup vorstellen, welches die fachlichen Capabilities und ihre Zusammenhänge darlegt. Das Modell ist in den letzten zwei Jahren von Mitgliedern der Arbeitsgruppe erstellt worden und soll eine Übersicht der erforderlichen Aufgaben geben, die im Kontext einer Open Source Compliance erforderlich werden. Es eignet sich auch, um die unterschiedlichen Werkzeuge abzubilden oder sich klar zu machen, welche Funktionalität sie abdecken.
Jan wird den Talk auch benutzen, um die Anbieter der Werkzeuge zu motivieren, Ihre Werkzeuge gegen das Modell zu mappen.
In einem zweiten Talk wird Grigory Markin im Dev-Room Software Composition das Open Source Werkzeug TrustSource DeepScan sowie den gleichnamigen, freien online Service DeepScan vorstellen. Die Lösung kann eingesetzt werden, um die erforderlichen Informationen (Copyright & Lizenzen) zu bestimmen, welche für eine rechtlich konforme Nutzung erforderlich sein können:
TrustSource DeepScan – How to effectively excavate effective licenses
In diesem 15 minütigen Talk werden Grigory und Jan kurz die Herausforderung der „effective“ Lizenzen anreißen und auf die unterschiedlichen, technischen Möglichkeiten und Herausforderungen der automatisierten Lizenzanalyse u.a. mit Hilfe der Similarity-Analyse eingehen. Abschließend werden kurz das Werkzeug, der gegenwärtige Arbeitsstand und die nächsten Schritte dargestellt.
Sie haben an dem 6./7. Februar keine Zeit, würden aber gerne mehr erfahren?
TrustSource v1.9 released!
We are happy to announce our latest release of TrustSource, version 1.9 to arrive Sept. 10th 2019!
With our v1.8 we have introduced a more detailed versioning schema allowing a closer matching between the code repos and the scan results by introducing support for branch and tag. In this release on of the major updates is the new approval, which allows to specify a combination of versions which shall be taken for an approval. But besides this, there is even more:
New Features:
- Improved Approval Process:
The new approval will be started as the former version. But a wizard will guide you through the steps. You will be able to give the approval a particular name, select the modules and analysis versions to apply. When you are confident with your selection and issue the approval request, TrustSource will generate all relevant documentations (Notice File, if required a SOUP file – see below – and a new compliance report) and process the request towards the compliance manager(s).
They will find the information in their inbox and can immediately dive into the new compliance report. - Compliance Report:
The new compliance report will give a comprehensive summary of the project situation including legal and vulnerability status. Also it will the required documentation and unveil the degree of completion. Also the report will outline the changes in component status a project manager has made will be shown. Thus manual status changes will become immediately visible, comments on vulnerabilities having been muted will be available for review and more…. - DeepScan:
How often do you rely on the declared license? How many of us really dig deep to ensure that there is no little snippet of code containing another license? I probably better do not want to know. However, we proudly present DeepScan. This new service allows you to specify the URL of a component repository, which DeepScan then will assess for you in the background. It will search for all sort of data providing a relation to a license specification and present the findings to you. Give it a try! You might be surprised… - Support for Medical Device Directive Documentation:
In 2020 the European Medical Device Directive will force developers of software related to medical devices to clearly outline all third party software and track these changes and require these to register each change (UDI-ID). We prepare to support this procedure and already offer automatically generated SOUP-lists as well ass COTS-component management. Further steps to follow, sty tuned with our newsletter.
Improvements:
- Improved sorting and selections from lists
- Multi-license cases will be marked as warning as long as no decision about the license to use has been made, even if both licenses would result in no obligations. Thus all required decisions will be easy to identify.
- We were able to identify some inputs from scanners being misinterpreted, e.g. „>=“-version conditions, resulting in difficulties with the correct version matching. These cases will be properly resolved now.
OpenChain Spezifikation v1.2 verfügbar
Heute hat das OpenChain-Projekt die Spezifikation in der Version 1.2 veröffentlicht. Die Spezifikation kann hier in der englischen Version heruntergeladen werden. Die begleitende Information zum Release der Spezifikation findet sich hier.
Was ist OpenChain?
OpenChain ist ein Projekt der Linux Foundation, das sich zum Ziel gesetzt hat, das Vertrauen in die Nutzung von Open Source, insbesondere entlang der Wertschöpfungskette in der Software-Industrie zu erhöhen.
Wie wird das erricht?
Um dieses hochgesteckte Ziel zu erreichen, hat sich ein internationales Gremium aus Spezialisten gebildet, welches mit der OpenChain-Spezifikation einen Rahmen geschaffen hat, der Mindestanforderungen an betriebliche Abläufe und Dokumentation stellt. Damit soll in erster Linie ein bewusster Umgang mit Open Source im Unternehmen gewährleistet werden. Es besteht die Möglichkeit, seine Organisation im Zuge eines Self-Assessment gegen die OpenChain-Spezifkation zu prüfen bzw. zu zertfizieren. Zertfiizierte Unternehmen, sollten somit einem einheitlichen Standard im Umgang (EInkauf, Verarbeitung, Auslieferung) von Open Sourc eunterliegen.
Was sind die Limitierungen?
Die Spezifikation stellt Anforderungen an Prozesse und bietet somit einen Rahmen für die Organisationsgestaltung. Sie macht keine Vorgaben bzgl. spezifischer Dokumente oder der einzlener Artefakte, die zu erezeugen sind, um eine hinreichende Dokumentation zu erzeugen.
Wenn Sie mehr zu OpenChain erfahren wollen oder Hilfe bei dem Self-Assessment suchen, kontaktieren Sie uns!
22.2. Erfahrungen aus dem Aufbau von Open Source Governance
Am 22.2.2018 fand in Erfurt der 2. Compliance Day des Bitkom Arbeitkreises Open Source statt. Auf dieser Veranstaltung hat Jan in einem Vortrag Erfahrungen aus der Einführung von Prozessen und Policies zur Open Source Compliance vorgestellt. In diesen Vortrag geht Jan auf die Motivation und Herausforderungen der Einführung von Open Source Governance ein. Darauf aufsetzend stellt er ein umfassendes Konzept mit vier Säulen vor, welche nicht isoliert betrachtet werden sollten und gibt Hinweise, wie diese erfolgreich umzusetzen sind.
Der Vortrag kann hier heruntergeladen werden.
Informationen über weitere Veranstaltungen und des zum AK Open Source gibt es hier.