
Aktuelle Herausforderungen Open Source Compliance
Warum organisieren sich SAP, Siemens, Fujittsu, Toyota oder Orange unter dem Schirm der Linux Foundation im OpenChain-Projekt, das Standards im Umgang mit Open Source setzen will? Mit der zunehmenden Verbreitung von Software in alle Gegenstände und dem stetig steigenden Open Source Anteil, steigt auch die Notwendigkeit einer rechtlich konformen Dokumentation. Doch was verbirgt sich hinter der Anforderung? Warum ist das plötzlich so wichtig?
Zunächst zur Motivation; drei wesentliche Treiber tragen zur wachsenden Dringlichkeit bei:
- Wachsende Verteilung von Software-Komponenten
- Gleichzeitig steigt der Anteil von Open Source Software
- Zunehmende Automatisierung der Software-Entwicklung und Verbreitung von Continuous Integration und Delivery-Ansätzen
Aus dieser Gemengelage entsteht ein sensibles Umfeld. B erhöht zwar die Geschwindigkeit der Lieferung, verlagert aber gleichzeitig Teile der Wertschöpfung in die Hände Dritter. In Verbindung mit C kann bei jedem neuen Bau der Software eine neue Zusammensetzung entstehen, da ja alle Beteiligten – also auch die Dritten – stets weiterentwickeln.
Open Source Compliance - Risiken kennen
Dabei muss man sich vergegenwärtigen, dass solche Abhängigkeitsbäume nicht nur zwei oder drei Ebenen haben, sondern in der Regel bereits bei einem einfachen Modul mehrere hundert Komponenten und durchaus vier bis sieben Hierarchiestufen umfassen. In größeren Projekten sind’s schnell mehrere tausend Komponenten.
Ändert sich nun die Lizenz einer der Sub-Komponenten oder es wird eine Abhängigkeit mit MIT -Lizenz durch eine mit Apache-Lizenz ersetzt, entstehen für diese Subkomponente neue Veröffentlichungspflichten (Attribution = Zuschreiben des Werkes zum Autor). Und gerade die Veröffentlichungspflichten sind es, die gerne unterlassen werden.
Dabei ist auch hier Vorsicht geboten! Wie viele andere Open Source Lizenzen berechtigt auch die Apache-Lizenz den Gebrauch nur unter der Voraussetzung, dass die Lizenz und Veränderungen entsprechend deklariert werden. Wer eine Komponente unter Apache-Lizenz einsetzt, es jedoch versäumt, dies zu erwähnen, den und den Lizenztext beizulegen oder seine Anpassungen zu deklarieren, verliert das Recht, die Komponente zu nutzen!
Die rechtlich Folgen einer Missachtung können erheblich sein. Versäumt es ein Unternehmen, entsprechende Mechanismen zu schaffen, die geeignet sind, ein fehlerhaftes Inverkehrbringen zu unterbinden, so steht der verantwortliche Bereichsleiter bzw. Geschäftsführer in der Haftung. Solche Urheberrechtsverletzungen im gewerblichen Kontext sind keine Kavaliersdelikte, sondern eine Straftat, welche bei Bekanntwerden die Staatsanwaltschaft auf den Plan ruft. Als Strafe droht für die betroffenen Verantwortlichen in Deutschland ein Gefängnisaufenthalt.
Durch die zunehmende Verbreitung von Software in alle Arten von Geräten (A) verschärft sich das Risiko, da die Möglichkeit, Zugang zu der Software zu erhalten und sie in ihre Bestandteile zu zerlegen, ebenfalls steigen. Es ist vermutlich nur eine Frage der Zeit, bis windige Gestalten hieraus ein Geschäftsmodell ableiten. Auch für enttäuschte Mitarbeiter bietet dieser Bereich ein geeignetes Feld für einen Rachefeldzug.
Auszug Apache 2.0 Lizenz:
(…) 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (…)
Im Kontext von Serienprodukten liegt die enorme Bedrohung dabei nicht unbedingt nur in der strafrechtlichen Konsequenz für den betroffenen Manager, auch ein Rückruf der in Umlauf gebrachten Produkte könnte eine zwingende Folge sein, wenn sich das Problem nicht anderweitig heilen lässt, beispielsweise durch Nachreichen einer Dokumentation an alle bisherigen Käufer oder vergleichbarer Ansätze.
Wie einen dies treffen kann, hat Dr. Ibrahim Haddad (Samsung Open Source) in seiner Präsentation „Guide to Open Source Compliance“ (2) dargestellt. Er beschreibt einen Fall von Cisco. Cisco kaufte 2003 die Firma Linksys für gut 500 Mil USD. Linksys hatte in seinem WRT54G Broadband-Router ein Chipset von Broadcom verbaut. Dieses wiederum nutzte angepassten Linux-Code, den die Firma CyberTAN Broadcom zur Verfügung gestellt hatte. Linux ist GPL-lizensiert, damit sind Anpassungen und damit verbundener Code veröffentlichungspflichtig. Die FSF hat geklagt und am Ende hatte Cisco nicht nur viel schlechte Presse, sondern auch einen Schaden von gut 50 Mil USD und musste seinen Code und damit eine Menge teuer erworbenes Intellectual Property ebenfalls veröffentlichen.
Bleibt also die Frage, wie sich diese Risiken eliminieren lassen?
OS Compliance - Pflichten erfüllen
Es gibt bereits eine Vielzahl von Herangehensweisen und Prozessen. Den aus unserer Sicht vollständigsten Ansatz beschreibt die OpenChain Spezifikation(3). OpenChain (4) ist ein Projekt der Linux-Foundation. Es hat sich zum Ziel gesetzt, Sicherheit und Vertrauen bezüglich des Einsatzes von OpenSource entlang der Software-Wertschöpfungskette zu gestalten. Die Spezifikation liegt derweil in der Version 2 vor und ist auf dem Weg, zu einem ISO-Standard erhoben zu werden.
Sie beschreibt ein Set von sechs Zielen und den Anforderungen, um diese Ziele zu erfüllen. Unternehmen, die diese Ziele erfüllen, können als OpenChain-konform angesehen werden und haben somit ein entsprechendes Compliance-System in ihrer Organisation verankert. Nachstehendes Bild gibt einen Überblick der Anforderungen.

Neben der Anforderung an die organisatorische und prozessuale Gestaltung lässt OpenChain jedoch die Art der zu erzeugen Dokumentationsartefakte offen. Um diese Lücke zu schließen, sind im Folgenden die Elemente vorgestellt, mit deren Bereitstellung sich die oben beschriebenen Risiken vermeiden lassen.
Zum einen ist es erforderlich, Transparenz über den Inhalt zu schaffen, also eine Art Stückliste mitzuliefern. Diese Stücklisten, oder auch als Bill of Materials bezeichnet, haben bereits einen Standard für die Beschreibung erhalten, im ebenfalls unter der Linux Foundation gestaltetem SPDX-Projekt (5). Dort wird ein maschinenlesbares Format beschrieben, welches die Inhalte einer Komponente beschreibt. Es erlaubt eine entsprechend feingranulare Darstellung der Inhalte und eignet sich für die Repräsentation einer Stückliste.
Für jede OSS-Komponente in dieser Stückliste sind dann zusammenzustellen:
- Informationen, die die Software konkret identifizieren (Version)
- Die Lizenz, unter der die Komponente eingesetzt wird (s. u. Mehrfachlizenz)
- Änderungen, die an der Komponenten vorgenommen wurden, wenn die Lizenz dies erfordert
- In einigen Fällen erfordern Lizenzen auch die Nennung der Autoren (Copyright-holder)
Wir unterstützen Unternehmen dabei, die Prozesse und Verantwortlichkeiten zu identifizieren und spezifikationskonform aufzusetzen. TrustSource integriert dem konformen Prozess optimal in die Arbeit des Entwicklers und erleichert somit das Erfüllen der OpenChain Anforderungen.
Im Kontext einer Distribution ist darüber hinaus in einigen Fällen der Lizenztext hinzuzufügen. Weiterhin gibt es einige Lizenzen, die auch im Kontext einer binären Distribution die Bereitstellung des Quelltextes erfordern. In diesem Fall wäre ein Angebot zur Übermittlung der Quellen beizulegen, die sogenannte „Written offer“.
Diese Informationen lassen sich nicht immer einfach ermitteln. Es ist aber möglich, einige davon aus den unterschiedlichen Quellen und Repositories der jeweiligen Projekte zusammenzutragen. TrustSource kenn beispielsweise die Abhängigkeiten von gut 20 Mil Open Source Komponenten in allen Versionen, was wiederum gut 500 Mil Abhängigkeiten darstellt. Hier ist schon eine Menge Arbeit getan, jedoch wächst der Pool an Open Source Software täglich. Daher stehen diverse Prüf- und Verifikationsmechanismen zur Verfügung.
Um diese Aufgaben zu erleichtern, hat TrustSource den Notice-File-Generator entwickelt. TrustSource setzt im Paket-Manager der jeweiligen Entwicklungsumgebung an und erzeugt das Bill of Materials der tatsächlich eingesetzten Software-Komponenten. Dieses wird anschließend vom Legal Check Service, der die Lizenzen kennt, im Kontext des Projektes auf Veröffentlichungspflichten sowie andere Verpflichtungen geprüft. Im Ergebnis entsteht eine Ampel, die es erlaubt, automatisiert den Build zu stoppen, wenn Verletzungen auftreten.
Weiterhin verfügt TrustSource über einen Notice-File-Generator. Dieser erzeugt basierend auf dem Bill of Materials und den Erkenntnissen aus dem Legal Check das Grundgerüst für das Notice File. Diese Vorlage wird anschließend mit den Informationen zu den Komponenten aus der geteilten Datenbank gefüllt. Somit bleibt dem Bearbeiter nur noch die bestehenden Lücken zu schließen. Seine Eingaben werden wiederum der Komponenten DB hinzugefügt und stehen dem nächsten zur Verfügung.Einfacher lässt sich eine rechtlich konforme Dokumentation derzeit nicht herstellen.
Open Source Compliance - Sonderfälle klären
Nun ist die Welt leider nicht rund und es gibt noch tieferliegende Herausforderungen im Bereich der Compliance.
Multi-License
So gibt es beispielsweise Komponenten, die nicht nur unter einer Lizenz, sondern unter mehreren veröffentlicht werden. In einem solchen Fall muss sich der Entwickler festlegen, unter welcher Lizenz er die Komponente einsetzen will. Diese Entscheidung sollte sich im Notice-File entsprechend wiederfinden, da ja hier die entsprechenden Anforderungen zu erfüllen sind.
TrustSource weist auf diesen Multi-License-Fall hin, fordert eine Entscheidung ein und verwendet anschließend die gewählte Lizenz, bis sie wieder geändert wird. Die Entscheidung wird dokumentiert und kann begründet werden.
Deklariert vs effektiv
Ein anderer, sehr kritischer Fall, sind fälschlich deklarierte Lizenzen. So kann es beispielsweise vorkommen, dass ein Paket als Apache 2.0 Lizenz deklariert ist, jedoch weitere Drittbausteine einsetzt, die einer anderen Lizenz unterliegen. Das ist eher die Ausnahme als die Regel, aber es birgt ein erhebliches Risiko. Beispielsweise die Komponente Mapfish kommt als BSD lizensiert daher. Dennoch setzt sie unter anderem das Sencha-Framework ein, welches eine kommerzielle Lizenz erfordert.
Für die rechtliche Wirkung ist die effektive Lizenzierung wichtig, nicht die deklarierte. Die effektive Lizenzierung entsteht durch die Bemerkungen im Quellcode. Der Hinweis „AGPL-2.0“ in einer einzelnen Quelldatei kann ausreichen, eine effektive Lizenzierung dieser Datei unter AGPL zu erzeugen. Natürlich gilt, „Wo kein Kläger, da kein Richter“. Wer jedoch ein Produkt in den Markt bringt, sollte sich von diesen Gedanken nicht leiten lassen.
Um diese Risiken auszuschalten, hat TrustSource den Service DeepScan entwickelt. Mit Hilfe von DeepScan kann ein Repository bzw. eine Reihe von Repositories noch einmal überprüft werden. Dies erlaubt es, eine gesamte Dependency-Hierarchie vollständig auf Hinweise nach Lizenzen zu untersuchen. Die Ergebnisse werden übersichtlich in einer Zusammenfassung angezeigt und kritische Elemente lassen sich direkt aus dieser Übersicht ansteuern.
Keine Lizenz
Eine weitere Sondersituation ist der „No license“-Fall. Tatsächlich gibt es einige Komponenten, die über gar keine Lizenzdeklaration verfügen. Einige Autoren haben ihre Ergebnisse „public domain gestellt“. Es mag hier zum Ausdruck kommen, dass sie ganz philantrophisch die Komponente allen zugänglich machen wollen. Das ist nett und auch sehr löblich. Leider ist es aus rechtlicher Perspektive eine Katastrophe, da „public domain“ vielleicht im englischsprachigen Raum eine Bedeutung haben mag, jedoch weder im angelsächsischen Recht noch im deutschen gibt es hierzu eine Rechtsfestlegung. Auch ist „public domain“ keine bekannte, gültige Lizenz.
Somit liegen trotz der Deklaration alle Rechte beim Urheber. Es ist rechtstechnisch gesehen, verboten, diese Komponenten zu nutzen, zu verändern zu verteilen oder gar zu verkaufen! Die „No license“ gehört auf jede Black-Liste ganz nach oben.
Um solche Fälle aufzulösen, bietet es sich an, den Autoren zu kontaktieren. Man kann ihm freundlich die Thematik erklären und ihn bitten, eine Lizenz, gegebenenfalls sogar einen Vorschlag anbei, hinzuzufügen. Erfolgt dies jedoch nicht, birgt die Verwendung ein hohes Risiko. Denn auch wenn jemand heute die Annahme vertritt, er möchte großzügig sein, ist ein Leben gerne mal wechselhaft und die Meinung kann sich ändern. Wer sein IP nicht gefährden will, sollte Abstand von solchen Komponenten halten.
TrustSource weist Komponenten ohne Lizenzen stets als Verletzung aus. Auch hier lässt sich der Hinweis durch den Benutzer übersteuern, wenn er das Risiko eingehen möchte, ein Compliance Manager erhält jedoch stets den Hinweis, dass solche Komponenten in dem zu begutachtenden Konstrukt verbaut sind.
Fazit
Zusammenfassen lässt sich erkennen, dass Open Source Compliance zwar eine wachsende Herausforderung darstellt, es jedoch auch hinreichend Initiativen und Lösungen gibt, den daraus entstehenden Aufwand erheblich zu reduzieren.
Die Gestaltung einer Open Source Policy – also der Definition von Verhaltensregeln, Vorgehen und Verantwortlichkeiten bei er Nutzung von Open Source – kann ein erster Schritt sein. Unter https://www.trustsource.io/resources finden sich Vorlagen und Hinweise, wie sich eine Open Source Governance erfolgreich aufsetzen lässt. Die SaaS-Lösung TrustSource stellt eine erhebliche Unterstützung für die Einführung und Aufrechterhaltung einer effektiven Open Source Governance dar.
Literaturhinweise:
(1) Welche Herausforderungen die Compliance beantworten muss, findet sich in dem Artikel „Aktuelle Herausforderungen der Open Source Compliance“.
(2) Dr. Ibrahim Haddad (Samsung), „Guide to Open Source Compliance“, https://de.slideshare.net/SamsungOSG/guide-to-open-source-compliance , Slide 62
(3) OpenChain Spezifikation v2.0 (deutsche Übersetzung) https://github.com/OpenChain-Project/Specification-Translations/tree/master/de/2.0.
(4) OpenChain Projekt s. https://www.openchainproject.org ACHTUNG! Nicht zu verwechseln mit dem gleichnamigen OpenSource Blockchain-Projekt!
(5) SPDX-Projekt, s. https://spdx.org
Erweiterung des Visual-Studio-Plugins für .Net-Framework

Gestern hatten wir die Freude, das für .Net-Framework-Projekte erweiterte Visual Studio Plugin bereitzustellen. Wie vor einigen Wochen angekündigt, kann das Visual Studio Plugin nun .Net-Core und .Net-Framework-Projekte parallel scannen. Am einfachsten lässt sich das Plugin über dne Visual Studio Marketplace (kostenfrei) beziehen. Da das Plugin selbst Open Source ist, findet sich der Code auch auf github.
Ausgehend von unserer Intiative, unsere TrustSource Plattformauch den Microsoft-Entwicklern zu öffnen, haben wir nun beide Welten .Net-Framework und .Net-Core in einem Plugin vereint. Das ermöglicht es, beide Teilprojekte in einer Risk- und Compliance Lösung zu behandeln.
In einem nächsten Schritt werden die Commandline-Fähigkeiten der kombinierten Lösung ausgebaut, damit sie sich leicht in CI/CD-Lösungen integrieren lässt. Wir erwarten das Release gegen Ende des Monats.
Wir freuen uns jederzet über Informationen, Feedback und Anregungen zum Gebrauch und Einsatz unserer Plugins. Zögern Sie also nicht, uns zu kontaktieren und Ideenzu äußern.
Neues Release v1.7 bringt Notice-File-Generator
Wir freuen uns, endlich unseren Notice-File-Generator vorzustellen. Mit Hilfe des Notice-File-Generators ist es möglich, die leidige Arbeit des Zusammenstellens von Lizenzinformtionen auf wenige Clicks zu reduzieren.
Für gescannte Projekte ermittelt TrustSource die Anforderungen jeder Komponenten-/Lizenz-Kombination im jeweiligen Projektkontext und generiert daraus die erforderliche Information für den Notice-File. Sobald Änderungsnotizen oder Autoren-Angaben erfordelrich werden ergänzt TrustSource auf Basis vorhandener Informationen oder fordert diese Information ein. Durch die Shared-Component-Knowledgebase ist die ggf. erforderliche Recherche-Aufgabe nur einmal durchzuführen und für alle Plattformbenutzer verfügbar. Das reduziert die Aufwände für das Clearing erheblich!
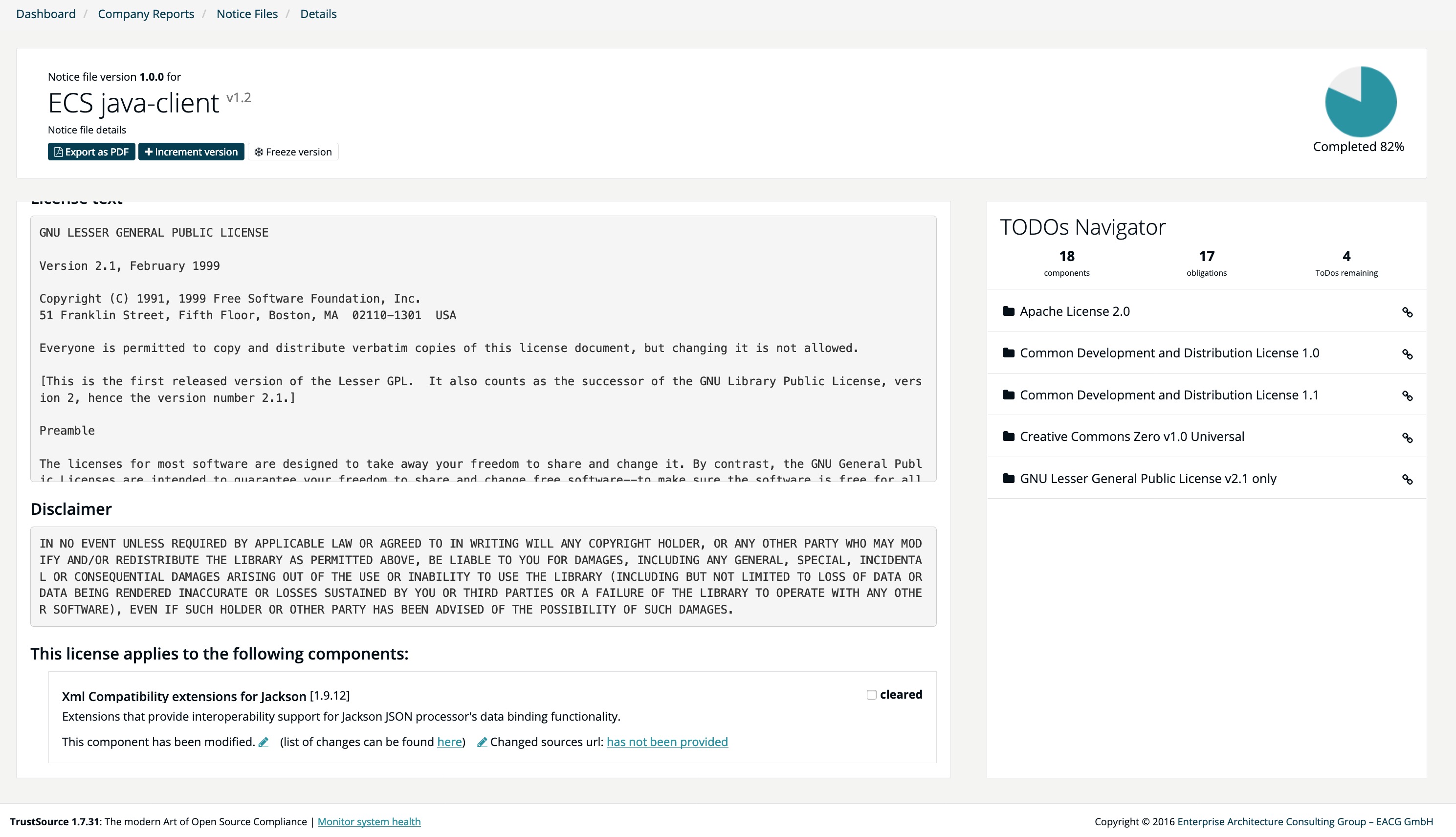
Zudem sind im Zuge dieses Updates einige der Plugins renoviert, bzw. um die Fähigkeit des Build-Breaks sowie die Proxy-Nutzung erweitert worden. Mit Hilfe des Proxys lassen sich nun Corporate Firewalls leichter überwinden. Der Build-break erlaubt es, auf die Auswertung der Daten zu reagieren und im Falle von Violations den Build direkt anzuhalten.
Weiterhin ist es durch die neue Benutzerverwaltung möglich, sich in den Free-accounts auch mit der Github- oder LinkedIn-ID anzumelden. Zudem unterstützt das neue Identity Management die Integration von Multi-Faktor-Authentifikation (Corporate+) und das Multi-Role-Assignment. Somit word es möglich, einem Benutzer gleichzeitiig mehrere Rollen und somit Zugriff auf die damit verbundenen Services zu gewähren. Die Anbindung von LDAP und anderen Identity-Providern wird hierdurch ebenfalls erheblich vereinfacht.
Mehr Informationen zu dem Release finden sich hier
Neuer Scanner für .Net-Core Projekte
Wir freuen uns, heute ein weiteres Werkzeug in der Familie der TrustSource-Integrationen bereitzustellen: Den .Net-Core-Scanner. Die plattformunabhängige Lösung findet sich in unserem öffentlichen Github-Repo für DotNet-Integrationen.
Das Werkzeug erlaubt es, .Net-Core-Projekte zu scannen und überträgt die gefundenen Abhängigkeiten an die TrustSource-Plattform zur weiteren Analyse. Dort werden die identifizierten Komponenten bezüglich Lizenzen und Schwachstellen geprüft und im Kontext des Projektes die aus dem Einsatz resultierenden rechtlichen Verpflichtungen abgeleitet.
Das Werkzeug besteht aus zwei Teilen: Der erste Teil ist der Scanner selbst. Er löst die Abhängigkeiten auf und sammelt die zu übermittelnden Daten. Der zweite Teil is die Konsolenanwendung, welche des ermöglicht, den Scanner über die Command-line zu steuern. Wenn im lokalen Arbeitsverzeichnis ausgeführt, reicht folgende Kommandozeile aus, um ein komplettes Projek tzu analysieren:
$ dotnet TS-NetCore-Scanner.dll -user „user@domain.com“ -key „TrustSource Key“
Die Konsolenanwendung und der Scanner sind ebenfalls in .Net-Core entwicklet und daher weitgehend plattformunabhängig. Das zugehörige Visual Staudio Plugin, welches das Tool kapselt und in die Visual Studio IDE einbindet, ist jedoch derzeit nur unter Windows verfügbar. Wer der Meinung ist, er braucht es auch auf anderen Plattformen, möchte sich gerne bei uns melden.
Damit schließen wir endlich eine wichtige Lücke in unserer Werkzeugunterstützung. Zusammen mit dem erweiterten Nuget-Crawler können die .Net-Core-Entwickler nun den gleichen Komfort eines qualitativ hochwertigen Open Source Management genießen. Aber dabei soll es nichht bleiben, wir planen mehr:
In den kommenden Wochen, werden wir in diese Lösung die Möglichkeit integrieren, auch .Net-Framework-Projekte zu scannen. Bisher gibt es dafür eine kleine Cosole-App, das soll aber genauso komfortabel werden.
Wir haffen, damit den Komfort der TrustSource-Plattform auch für die Microsoft Entwickler besser verfügbar zu machen. Wir sind stets daran interessiert, die Lösung zu verbessern und auf die Bedürfnisse unserer Kunden anzupassen. Zögern Sie also nicht, uns mit Vorschlägen und Anregungen zu kontaktieren!
OpenChain Specification v1.2 in Deutsch verfügbar!
Dank der Arbeit einer Hand voll Freiwilliger, gibt es jetzt die gegenwärtig aktuelle OpenChain Spezifikation in der Version 1.2 auch in deutscher Sprache!
https://www.openchainproject.org/news/2018/11/07/openchain-specification-in-german
Wir danken den Mitgliedern des Übersetzungs-Teams - sind ein wenig stolz darauf, auch einen Beitrag geleistet zu haben - und wünschen viel Spaß mit dem Umsetzen! Falls es Fragen gibt, stehen wir Ihnen gerne zur Seite!
Reflexion BFOSS 2018

Das war sie nun, gestern, die BFOSS 2018. Beachtlich, wie voll der Erfurter Kaisersaal geworden ist. Gegenüber dem letzten Mal ist wiederum eine erhebliche Steigerung der Teilnehmerzahl festzuhalten. Das entspricht dem gefühlten Druck, der zunehmend auf dem Thema liegt.
Ausgehend von einer Einführung in die Problematik wurden durch die Redner unterschiedliche Erfahrungen und Ansätze vorgestellt, wie sich Herstellerfirmen den Herausforderungen der OS-Governance (OSG) nähern. Mit 8 Vorträgen war das Programm voll und intensiv.
Interessant war zu sehen, dass sich die vorgestellten Ansätze zwar in Fokus, Gestaltungstiefe und jeweiliger Ausführung unterschieden, jedoch in der Ambition und dem Lösungsprozess vergleichbar sind:
- Integration der Governance in die Tool- bzw. Build-Chain (Fail-fast)
- Automatisierung bei der Analyse der relevanten Lizenzinformationen
- Möglichst automatisierte Komposition der BoM
- Bereitstellen einmal ermittelter Informationen für spätere Nutzung
Erstaunlich war für mich, wie wenig Fokus auf den Governance-Prozess an sich gelegt wurde. Das mag zum einen an den nach wie vor hohen fachlichen Anforderungen an die Werkzeuge liegen, die noch zu lösen sind. Zum anderen an den Protagonisten, die ja zumeist aus den technischen Bereichen stammen und sich daher mehr mit der technischen Lösung als mit dem Nachhalten der Ergebnisse beschäftigen.

Sehr erfreulich, insbesondere für uns als TrustSource, ist die übergreifende Erkenntnis, dass dieser Schritt ohne Werkzeugunterstützung nicht abbildbar ist. Aus meiner Sicht ist uns Ansatz, alles rund um die Stellen zu automatisieren, die man kennt und die rote Lampe zu zünden, wenn es manuelles Eingreifen braucht aufgrund der gegenwärtigen Situation vermutlich auch der pragmatische und zuverlässige. Ergänzend zu dieser Betrachtung, wurden darüber hinaus diese drei wesentlichen Herausforderungen immer wieder unterstrichen:
- Einführung von Open-Source Governance ist eine Aufgabe für sich. Obwohl es eigentlich eine Selbstverständlichkeit sein sollte, wie das Händewaschen oder das Verständnis, niemandem etwas wegzunehmen, so ist die Notwendigkeit von IP-Schutz / OSG doch nicht allen präsent. Diese Bewusstseinsbildung ist in einer Organisation ein harter und zäher Prozess, der viel Aufmerksamkeit erfordert.
- Informationslage ist oft unzureichend. Software-Entwickler sind keine Rechtsanwälte und dementsprechend sind stellenweise die Grundlagen für die rechtssichere Nutzung, bzw. Bereitstellung von Komponenten gar nicht hinreichend vorhanden. Aus den Gesprächen lässt sich eine Tendenz ableiten, je hardware-näher bzw. älter die Komponenten, desto aufwänder die Aufbereitung der erforderlichen Information.
- Unternehmensübergreifende Zusammenarbeit wird zum Thema. Zwar kam eine Großzahl der Vorträge aus dem Siemens/Bosch-Umfeld, jedoch lies sich generell der Wunsch nach mehr Unterstützung in der Governance-Arbeit vernehmen. Dabei wurden unternehmensübergreifende Ansätze für Repositories wie bspw. ClearlyDefined in den Fokus gerückt. Folgerichtig hat sich der AK Open Source des Bitkom dieses Thema auch als Fokus für nächstes Jahr vorgenommen.
Gerade der letzte Aspekt wurde auch in den vergangenen Monaten bereits des öfteren diskutiert. Grundsätzlich ist die Idee gut, Open Source-Mechanismen zu nutzen, um Open Source besser zu organisieren. Aber was bedeutet das?
Shared clearing - Gedankensammlung
Im Grunde genommen geht es primär um das „Clearing“ der Lizenzinformationen für das Notice-File, also die Begleitinformation, die einem Produkt, welches Open Source einsetzt, beigelegt werden muss, um die Nutzungsrechte an der eingesetzten Software sicherzustellen.
Das Konzept
Hierbei sind aufgrund der nicht standardisierten Grundlage und den stellenweise unklaren, unvollständigen oder auch fehlerhaften Lizenzbedingungen der ggf. zum Einsatz kommenden OS-Artefakte erhebliche Klimmzüge zu veranstalten, um eine rechtlich korrekte Dokumentationslage als Einsatzvoraussetzung zu schaffen.
Die Idee ist nun, dass ein Unternehmen A nach den Klimmzügen die Früchte seiner Arbeit einem crowd-sourcing-artigen Gremium überträgt und somit den anderen Unternehmen diese Arbeit abnimmt. Analog könnte das partizipierende Unternehmen aus dem bereitgestellten Pool schöpfen, um sich selbst Arbeit zu ersparen. Wenn der Pool öffentlich wäre, gäbe es hier auch keine wettbewerbsbeschränkenden Aspekte zu beachten.
Vertrauen als Basis
Dieser Ansatz erfordert jedoch nicht nur die Bereitschaft, seine Arbeitsergebnisse zu teilen, es erfordert auch Vertrauen. B muss A vertrauen, dass er seine Arbeit richtig und vollständig gemacht hat. Andernfalls müsste B die Ergebnisse von A zumindest noch einmal prüfen, was vermutlich dem eigenen Clearing nicht wesentlich nachsteht, will man es „vollständig“ prüfen.
Alternativ könnte man sich einen mehrstufigen Reifeprozess vorstellen. A stellt eine Ergebnis ein, B prüft es (weniger Aufwand als A) und bestätigt es, wenn die Prüfung erfolgreich ist. Somit könnte C tatsächlich mit recht hohem Vertrauen auf das Ergebnis zugreifen.
Anforderungen an das Clearing
Bleibt die Frage, ob ein Clearing unabhängig vom Anwendungsfall erfolgen kann. Denn das Arbeitsergebnis kann für einen spezifischen Anwendungsfall vollständig „cleared“ sein, für einen anderen noch nicht. Das ergibt sich aus den erheblich abweichenden Anforderungen, die sich aus der Kommerzialisierung, der technischen Nutzung oder der Art der Distribution ergeben.
Da es vermutlich wenige Lizenzen gibt, die eine Dokumentation untersagen, könnte man sich beim Shared-Clearing auch darauf einigen, immer die maximale Dokumentation herzustellen. Das bedeutet, immer für alle Komponenten die alle üblicherweise erforderliche Dokumentation einzufordern. Somit wäre sichergestellt, dass ein einmal eingestelltes Paket, alle Anwendungsfälle abdeckt.
Da dies wiederum erheblich erhöhte Aufwände für den Erstbereitsteller bedeuten könnte, könnte sich diese Forderung negativ auf die . Um dennoch den Ansatz nicht fallen zu lassen, wäre ggf. zu überlegen, ob nicht die Dokumentation des Anwendungsfalles, für den es erzeugt wurde, eine zu wichtige Meta-Information an dem Artefakt wäre. Damit wäre es einem Nutzer möglich, die Eignung bzw. das Risiko für den eigenen Anwendungsfall abzuschätzen.
Haftung im Shared-Clearing
Da der Einsatz hier ja in einem unternehmensübergreifenden Kontext stattfindet, stellt sich die Frage nach der Haftung. Was passiert, wenn B einen Produktrückruf aufgrund des nachweislich unvollständigen, bzw. fälschlichem Clearings durch A zu verkraften hat?
Der natürliche Reflex jedes wirtschaftlich Handelnden ist es, außerordentlichen Aufwände an möglichst an Dritte weiterzureichen. Ist A für diese Information haftbar? Das ist sicherlich etwas, das es im Rahmen des Contributor Agreements zu klären gilt. ClearlyDefined hat dies durch den Open-Source-typischen Haftungsausschluss und eine Schadenslimitierung auf 5 USD. gelöst.
Das ist sicherlich die gute Voraussetzung, um die Bereitschaft für Kontributionen zu erhöhen. Es führt jedoch wieder zur verbleibenden Prüflast seitens des Benutzers. Somit bleibt die Frage offen, welche Arbeit ihm durch die Wiederwendung erspart bleibt. Die Vorstellung den Linux-Kernel einem Clearing zu unterziehen ist sicherlich gruselig. Die Vorstellung, eine als cleared bereitgestellte Version stichhaltig zu prüfen, erscheint mir jedoch nicht weniger gruselig.
Zertifizierung als Ergänzung bzw. Alternative?
Die Idee der verteilten Zusammenarbeit ist zwar gut und passt ins Genre, tangiert jedoch ein Thema, das sich komplett außerhalb dieser Welt bewegt. Dementsprechend schwierig gestaltet sich der Anpassungsprozess.
Möglicherweise wäre eine Zertifizierungsstelle der geeignetere Ansatz? Angenommen es gäbe einen Body, der sich den Schuh der Prüfung bzgl. eines Anwendungsfalles anziehen und eine Garantie für die Vollständigkeit bzw. Korrektheit des Clearings in Form eines Zertifikates abgeben würde.
Hierdurch würden sich die Bedürfnisse beider Welten vereinen lassen. Zum einen ließen sich die Ergebnisse teilen und wiederverwenden, zum anderen wären sie hinreichend überprüf- und belastbar, um tatsächlich Einsparungen zu erzeugen.
Diskutieren Sie mit uns!
Gerne lernen wir Ihre Sicht auf diese Aspekte kennenlernen. Diskutieren Sie mit uns oder teilen Sie uns mit, was Sie für richtig halten.
Version 1.6 released
Wir freuen uns, nach der Sommerpause nun endlich die Version 1.6 von TrustSource bereitzustellen. Auch mit diesem Release erweitern wir wieder den Leistungsumfang und verbessern bzw erweitern bereits bestehende Features:
Neue Features
- Vulnerability-alert - Es hat ein wenig gedauert, aber wir haben es geschafft! TrustSource informiert Sie nun, falls neue Schwachstellen bezüglich der von Ihnen in Ihren Projekten verwendeten bzw. eingesetzten Komponenten bekannt werden. Das betrifft auch alte Versionen ihrer Projekte!
- "Action required" items in inbox -Insbesondere für Compliance Manager wird unsere "Aktion erforderlich" Mailbox eine Arbeitserleichterung sein. bereits auf dem Dashboard finden sich Approval-reqeuests und andere Aufgaben, welche Ihre Aufmerksamkeit erfordern. Mit Hilfe von Deep-Links können Sie direkt in die zugehörige Informationslage einsteigen.
- Dependency graph - Eine Liste ist schön und gut. Wenn es jedoch darum geht die Bedeutung einer Komponente im Kontext des Einsatzes zu verstehen, ist eine graphische Abbildung oft hilfreicher. Wir haben daher eine graphische Übersicht der Abhängigkeiten hinzugefügt. Sie können den Graphen konfigurieren (Kantenlänge, Punkgröße und Gravity) und die Hierachietiefe bestimmen. Die Farben zeigen den Komponenten-Status an.

Verbesserungen
- Überarbeitet Regeln und mehr Lizenzen - Basierend auf Erfahrungen und Austausch haben wir die Ergebnisse zu einigen Lizenzen überarbeitet. Auch konnten wir die LIzenzbasis wieder mit einigen neueren Lizenzen erweitern.
- Verbessertes maven Plugin - Das maven plugin wurde erweitert, um auch die Check-API zu unterstützen. Somit is es auch dem einzelnen Entwickler möglich, bereits an seinem Arbeitsplatz ein Feedback über die Eignung der Komponenten zu erhalten.
- Erweitertes Jenkins Plugin - Auch das Jenkins plugin haben wir in diesem Kontext um den Aufruf des check-APIs erweitert.
Bug-Fixes
- Name im Einladungsformular überarbeiten - Es ist jetzt möglich, den eigenen Benutzernamen bereits im Registrierungsformular zu überarbeiten, wenn man eingeladen wurde.
- Propagate delete aller Projektmitglieder - Das Löschen der Sichtbarkeitseinschränkung aller Module eines Projektes funktioniert wieder.
Die kommende Version v1.7 wird sich vor allem mit Sicherheit und neuen Login-Möglichkeiten (Github, etc.) sowie der Vereinfachung von Corporate SSO beschäftigen. Auch werden wir in dem Zuge das derzeitige Rollenmodell etwas flexibilisieren. AFlls Si emehr über unsere Roadmap eefahren wollen, kontaktieren Sie gerne unser Vertriebsteam!
Falls Sie noch aus Ihrer Sicht wichtige Features vermissen, freuen wir uns mehr darüber zu erfahren.
Wie TrustSource Ihnen hilft, Ihre Organisation OpenChain compliant auszurichten
Wenn Sie mehr zu OpenChain erfahren wollen, lesen Sie zunächst unseren Beitrag "OpenChain in a nutshell".
Die OpenChain-Spezifikation definiert sechs Ziele. Inhaltlich stellen fünf Ziele den nachhaltigen Umgang mit Open Source Software sicher. Dabei fokussieren vier auf die hausinterne Organisation und das fünfte auf die Unterstützungsleistung von Open Source Projekten. Das sechste Ziel betrifft die Bereitschaft, nach außen zu erklären, dass man sich an den inhaltlichen Zielen messen lassen will, also die Bereitschaft zu einer Zertifizierung hat.
Dieser Beitrag stellt die Ziele kurz vor und erläutert, wie TrustSource dabei hilft, die Ziele zu erreichen
Ziel 1: Klären und Bewusstsein der Verantwortung
In einem ersten Schritt geht es darum, die Aufgaben und Verpflichtungen innerhalb der Organisation zu klären. Dies findet üblicherweise seinen Niederschlag in einer Regelung (Policy), einer Gebrauchsanweisung für den Umgang mit Open Source Software. Diese beschreibt die Rollen sowie deren Verantwortung, klärt, wie mit einzelnen Fällen umzugehen ist und beschreibt die Prozesse, welche zu befolgen sind.
TrustSource stellt eine Standard-Policy zu Verfügung. Sie kann als Ausgangslage für die Definition Ihrer eigenen Policy dienen.
OpenChain fordert weiterhin, dass nicht nur eine Policy existiert, sondern dass diese auch dem Personal bekannt ist, sie also gelebt werden kann. Hierzu ist sicherzustellen, dass ein Großteil (min 85%) der Entwicklung nachweislich von dieser Policy Kenntnis haben.
TrustSource integriert ab Version 1.7 eine Learning-Plattform mit einem Satz an Kursen, welche den Ansprüchen eines OpenChain-konformen Kurstrainings gerecht werden und Lernkontrollen ermöglichen.
Ergänzend wird gefordert, dass Prozeduren für die Erhebung und Identifikation der genutzten Open Source Komponenten sowie die Ermittlung der damit einhergehenden Rechte, Pflichten als auch Verbindlichkeiten existieren.
TrustSource stellt einen Mechanismus bereit, der den Projektkontext erhebt und die Pflichten sowie Verbindlichkeiten aus dem Einsatz vor diesem Hintergrund auflöst. Änderungen sowohl an Bestand als auch den Zielen werden automatisch dokumentiert.
Ziel 2: Zuweisen von Verantwortlichkeiten
Da die gegenwärtige Dokumentationslage im Bereich der Open Source Komponenten stark zu wünschen übrig lässt, ist mit Rückfragen und Klärungsbedarf seitens der Downstream-Nutzer zu rechnen. Das kann Rückfragen zur Nutzung bzw. den Einsatzmöglichkeiten aber auch die Bestandteile selbst betreffen. Um den Anfragen zu begegnen, bzw. diese auf einfache Art qualifiziert entgegenzunehmen, fordert die Spezifikation die Definition und Kommunikation eines benannten Kontaktes, den „FOSS-Liaison“ oder im Deutschen eher passend: „FOSS-Kontakt“.
Weiterhin fordert die Spezifikation, dass die Kommunikation nach zuvor definierten Regeln zu erfolgen hat und hinreichend dokumentiert sein sollte. Dies ist insbesondere für später ggf. anhängige Gerichtsverfahren ausgesprochen wertvoll.
Mit Hilfe von TrustSource können Sie diese Aufgabe nach außen delegieren. Sie richten eine Mail-Adresse ein und alle Incoming-Requests werden vom TrustSource HelpDesk strukturiert bzw. nach den mit Ihnen erarbeiteten Verfahren abgearbeitet.
Um den Anforderungen dabei gerecht zu werden, ist es als erheblich für den Prozess anzusehen, dass eine hinreichende rechtliche Expertise auf dem einschlägigen Gebiet vorhanden ist. Diese darf gemäß Spezifikation sowohl durch interne als auch externe Ressourcen gestellt werden.
Ziel 3: Wahrnehmen der FOSS-Aufgaben
Das dritte Ziel widmet sich der Dokumentation der erzeugten Software, bzw. der eingesetzten Artefakte. Der Prozess, um eine Stückliste (Bill of Materials, kurz BoM) zu erzeugen, sollte hinreichend qualifiziert und dokumentiert sein. Qualifiziert bedeutet, dass der Prozess sich dazu eignet, die tatsächlich eingesetzten Komponenten aufzuzeigen und sicherzustellen, dass diese Information auch im BoM auftaucht.
Das soll jedoch nicht nur einmalig zu einem Zeitpunkt passieren, sondern muss kontinuierlich für jedes Release erfolgen. Insbesondere im Zuge von Continuous Deployment entsteht hieraus eine erhebliche Verpflichtung für die Aktualität und die Archivierung der Dokumentation, bzw. der BoMs. Eine manuelle Durchführung ist im hier nicht mehr denkbar.
TrustSource kann hier optimal unterstützen. Durch die Integration mit den Entwicklungswerkzeugen lässt sich zu jedem Zeitpunkt ein BoM erzeugen. Die einzelnen Versionen lassen sich speichern und archivieren. Durch den „Freeze Release“ Mechanismus können bestimmte Versionen gezielt via API exponiert bzw. als SPDX exportiert werden. Ein aktuelles BoM ist somit stets gegeben.
Die Spezifikation macht keine Vorgaben bezüglich der Inhalte eines BoM. Jedoch hat im Kontext der Linux-Foundation die Arbeitsgruppe SPDX - Software Package Data Exchange - Vorgaben für die Lizenzdokumentation einer Anwendung erarbeitet. Diese lösen das Problem nicht abschließend, bilden jedoch eine gute Grundlage für eine technische Dokumentation.
Das Erstellen des BoM allein reicht jedoch nicht aus, um einen sicheren Umgang mit FOSS zu gewährleisten. Je nach Anwendungsfall können die Bestimmungen der inzwischen gut 396 bekannten Lizenzen unterschiedliche Verpflichtungen auslösen. So spielen der Einsatzzweck, die Art der Kommerzialisierung oder auch die Form der Distribution eine erhebliche Rolle bei der Identifikation der zu erfüllenden Verbindlichkeiten oder der ausgelösten Pflichten.
Das ist insbesondere deshalb wichtig, weil einige Lizenzen bei Nichterfüllung der Verbindlichkeiten oder Pflichten das Nutzungsrecht entziehen. In anderen Worten: Das Recht zur Nutzung der Komponente erlischt, wenn die Verpflichtungen nicht erfüllt werden. Und der Einsatz ohne Nutzungsrecht im kommerziellen Kontext, ist kein Kavaliersdelikt mehr.
OpenChain fordert daher, dass eine rechtliche Prüfung stattfindet, welche Verbindlichkeiten und Verpflichtungen in dem jeweiligen Einsatzszenario zu erfüllen sind, um eine rechtskonforme Anwendung im jeweiligen Szenario sicherzustellen.
Hier spielt TrustSource seine besondere Stärke aus. Durch Kenntnis der Bedingungen und Verpflichtungen aus mehreren hundert Lizenzen und einer strukturierten Erfassung des rechtlichen Kontextes kann die TrustSource Regel-Engine die Bedingungen für die Nutzung automatisiert fallspezifisch ableiten und somit als List of Obligations für eine Abarbeitung zur Verfügung stellen.
Ziel 4: FOSS Compliance Artefakte bereitstellen
In dem vierten Ziel geht es darum, dass die Compliance Artefakte nicht nur erzeugt, sondern auch mit der erzeugten Software ausgeliefert werden. Es ist also sicherzustellen, dass die Artefakte vollständig und Teil der Software sind.
TrustSource unterstützt dies durch die Bereitstellung eines SPDX Dokuments des entsprechenden Moduls oder Projektes. Zukünftig wird neben dem SPDX auch ein komplettes Notice-File kompiliert und bereitgestellt.
Um rechtlich konform zu agieren, ist es erforderlich, Revisionssicherheit herzustellen. Das bedeutet, alte Versionen sind zumindest solange aufzuheben, bis sichergestellt ist, dass keine alte Version mehr im Umlauf ist. Das ist erforderlich, damit sich Fragen zu einem älteren Versionsstand auch auf einer gesicherten Dokumentenlage beantworten lassen.
TrustSource kann die Information zu allen in TrustSource erzeugten Version jederzeit wieder bereitstellen.
Auf dieser Basis ist es stets möglich, zu identifizieren, welche Komponenten wo eingesetzt wurden und unter welchen Bedingungen. Einerseits macht Dokumentation angreifbar, da auch dokumentiert ist, was nicht getan wurde. Andererseits führt es aber auch zu der Sicherheit, tatsächlich alles Erforderliche unternommen zu haben, um Rechtssicherheit herzustellen. Fehler sollten bei einem solchen Vorgehen rechtzeitig aufgedeckt werden können.
Ziel 5: Verstehen der Community-Verpflichtungen
Open Source ist keine Einbahnstraße. Man sollte nicht nur nehmen, alle Nutzer von Open Source sind eigeladen, auch mitzugestalten. Dies geschieht über Mitarbeit in den open Source Projekten, sogenannten Contributions.
Hierzu werden üblicherweise für ein Engagement hausinterne Ressourcen für das Open Source Projekt abgestellt, die entweder ganz oder teilweise an dem Projekt mitarbeiten. Je nach Intensität kann dies auf gelegentlicher Basis in Form von Bugfixes oder freiwilligen Ergänzungen oder aber als definierte Abordnung zum Kern des Projektes erfolgen. Je nach Intensität eröffnet es dem beitragenden Unternehmen Einfluss auf die Gestaltung des Produktes. Es ist auch denkbar, dass das Unternehmen ein eigenes Open Source Projekt ins Leben ruft.
Ob gelegentlich oder gezielt und strukturiert, welche Form auch immer gewählt wird, die Beiträge sind klar zu regeln. Dabei geht es um rechtliche Fragen wie Trennung von Arbeitszeit und Freizeit, Ansprüchen und Rechten aus den Beteiligungen sowie dem Prozess, zur Bereitstellung von Beteiligungen.
Das fünfte Ziel nimmt sich dem Thema des Rückspielens in die Open Source Community an und verlangt, dass es eine Policy gibt, welche den Umgang bzw. die Beiträge zu Open Source Projekten regelt. Analog zur Regelung für den Einsatz von Open Source im Unternehmen, ist auch hier auch für die hinreichende Verbreitung und Bekanntheit der Regelungen zu sorgen.
Auch die Regelung zur Beteiligung an Open Source Initiativen kann mit Hilfe der gleichen Mechanismen wie die Unterstützung zu G1 genutzt werden. Auch für die Gestaltung von Beiträgen bietet TrustSource eine Sample-Policy als Grundlage.
Es kann sein, dass die Regelung eine Beteiligung an Open Source Projekten verbietet. Für diesen Fall ist nur die Bekanntheit des Verbotes zu propagieren. Aus unserer Erfahrung bietet sich ein Verbot jedoch nicht an. Sobald ernsthaft Open Source eingesetzt wird, ist mit Fehlern in der eingesetzten Software zu rechnen. Diese aufgrund eines Verbotes für Beiträge nicht beheben zu können, wäre fahrlässig.
Es ist demnach ein Governance Prozess für die Beiträge zu definieren. Im Idealfall unterscheidet sich dieser nicht wesentlich von dem für eigene Produkte, um es für alle Beteiligten einfach in der Handhabung zu machen.
TrustSource stelle eine für beide Einsatzformen einheitliche Plattform mit umfangreichen Werkzeugen für die Prozessunterstützung zur Verfügung.
Ziel 6: Bestreben, die Konformität zu zertifizieren
Das sechste Ziel fordert die Bereitschaft der Organisation die Umsetzung der Anforderungen aus den Zielen 1-5 zu bestätigen. Dies ist derzeit mit Hilfe eines Self-Audits möglich. Die Webseite der OpenChain bietet hierzu einen Fragebogen und entsprechende OpenChain-Partner unterstützen die Umsetzung.
TrustSource bietet eine geeignete Plattform, um die Prozesse sicherzustellen. Dies ist bei den einschlägigen Parteien bekannt und vereinfacht die Klärung der Prüfungen.
Zusammenfassung
Zusammenfassend lässt sich erkennen, dass der unternehmensweite Einsatz von TrustSource einen Großteil der Komplexität einer OpenChain-konformen Ausrichtung einer auch größeren Organisation erheblich reduzieren kann. Es bleibt aber auch festzuhalten, dass OpenChain die Einführung von Prozessen und die Veränderung von Abläufen erfordert. Dies ist immer ein aufwändiges Unterfangen, das Zeit und Fokus erfordert.
Wir empfehlen daher, den Scope gezielt zu wählen. Es mag durchaus sinnvoll sein, nicht gleich auf Konzernebene mit der Einführung anzufangen, sondern sich zunächst auf einen einzelnen Entity zu konzentrieren. Mit den Erfahrungen und Erfolgsgeschichten lässt sich die Einführung in einem zweiten Bereich wesentlich schneller erreichen.
Auch hier kann TrustSource in der Enterprise-Version mit der Multi-Entiy-Option helfen. Diese ermöglicht es, einzelne Einheiten/Bereiche in einem Konto zusammenzufassen und übergreifend zu administrieren, jedoch mit bereichsspezifischen Policies oder Black- und White-listen zu versehen.
Auch für Unternehmen, die bereits in eineigen Bereichen andere Scanning-Werkzeuge nutzen, kann TrustSource zur Vereinheitlichung der Ergebnisse dienen. Durch die Möglichkeit, Scan-Ergebnisse an das TrustSource-API zu übermitteln bzw. SPDX-Dokumente zu importieren, kann TrustSource das Bindeglied über mehrere, ggf. bereits existierende, bereichsspezifische Werkzeuge dienen. Somit lässt sich die Prozesskonformität und somit eine einheitliche Governance unternehmensweit sicherstellen.
OpenChain in a nutshell
In den letzten Wochen erhalten wir immer öfter Anfragen zu OpenChain. Was ist das? Ist das wichtig?
Daher wollen wir hier eine kurze Zusammenfassung geben. Wer mehr darüber wissen möchte, ist herzlich eingeladen, uns direkt zu kontaktieren.OpenChain ist ein Projekt der Linux Foundation, welches sich zum Ziel gesetzt hat, das Vertrauen in den Einsatz von Open Source Software zu stärken. Hierzu hat die OpenChain einen Satz anAnforderungen entwickelt, deren Einhaltung den nachhaltigen Umgang mit Open Source sicherstellen.
„Open Source Komponenten einer OpenChain zertifizierten Organisation kann man vertrauen“
Die Spezifikation der Anforderungen ist öffentlich und kann auf der Webseite der OpenChain heruntergeladen werden. Sie definiert sechs Ziele, die sich wiederum in zehn wesentliche Anforderungen herunter brechen lassen. Besonders an der Spezifikation ist, dass Sie nicht nur die Anforderungen definiert, sondern auch Kriterien, welche das Erreichen der Anforderung sicherstellen.
Nachstehende Abbildung fasst die gesamte Spezifikation auf einer Seite zusammen. Bitte beachten Sie, dass für diese Darstellung einige inhaltliche Kürzungen erfordelrich waren. Um die Grundgedanken der Spezifikation zu verstehen, ist die Übersicht jedoch hinreichend.
Was bedeutet das im Allgemeinen?
Mit der Spezifikation ist ein erster Ansatz geschaffen, eine neue Orientierung im Umgang mit Open Source zu geben. Zwar ist es derzeit so, dass kaum eine Organisation ohne Open Source auskommt, dennoch behandeln die meisten Open Source noch recht stiefmütterlich. Das wiederum führt dazu dass die Nutzung von Open Source selbst aber auch die Nutzung von Produkten immer wieder rechtliche Probleme aufwirft.
Die Spezifikation ist dafür geeignet, einen nachhaltigen Umgang mit Open Source zu erzeugen. In größeren Organisationen, die es gewohnt sind, Vorgänge zu strukturieren, gewinnt diese Ansicht bereits an Akzeptanz. Es ist davon auszugehen, dass sich diese Erkenntnis auch mittelfristig im Einkauf der großen Organisationen durchsetzen und somit das Vorgehen an Bedeutung gewinnen wird.
Was bedeutet das für mich?
Wenn Sie Software erzeugen und oder diese an Dritte ausliefern, sollten Sie sich mit den Anforderungen der OpenChain vertraut machen. Die Wahrscheinlichkeit, dass der nächste Abnehmer eine OpenChain-Zertfizierung verlangt ist nur eine Frage der Zeit. Der Prozess zur Zertfiizierung ist ein langer Prozess, der sich nicht in wenigen Wochen erzwingen lässt. Daher ist eine frühzeitige Beschäftigung mit dem Thema zu empfehlen.
Holen Sie sich die Übersichtsgrafik als Poster!
Wenn Sie mehr bezüglich der OpenChain Zertfizierung derzeit eine Zertfizierung im Selbst-Zertfizierungsformat – benötigen, finden Sie diese auf der Webseite der OpenChain unter OpenChain/conformace.
Wenn Sie Kontakt zu uns zur Klärung von Fragen einer OpenChain-Zertifizierung aufnehmen wollen, können Sie uns hier kontaktieren.
Wenn Sie erfahren wollen, wie TrustSource Ihnen bei der Ausrichtung nach OpenChain hilft, lesen Sie hier mehr.
Release v1.5 verfügbar
Wir freuen uns, heute die Version 1.5 von TrustSource zur Verfügung zu stellen. Mit diesem Release haben wir vor allem die Reporting-Fähigkeiten gestärkt, um die in TrustSource existierenden Daten verfügbarer zu machen.
New Features
- PDF-your-Reports - Es ist jetzt möglich, alle Berichte auch in ein PDF zu überführen und entsprechend herunterzuladen bzw. zu speichern. Die PDFs erhalten in Kopf- und Fußzeile automatisch Versionummer und Zeitstempel, um Chaos zu vermeiden.
- Neues Beipackzettel - Mit diesem Release haben wir die Bill of materials-Funktion überarbeitet. Soweit möglich, verlinken die Komponenten nun auf die Origianllizenz aus dem jeweiligen Repository. Als Fallback wird eine Originallizenz aus TrustSource zur Verfügung gestellt.
- CVE-Impact Analyse - Mit dem neuen Bericht "CVE-Impact" ist es möglich, den Einfluss einer CVE auf das gesamte in TrustSource verwaltete Software-Portfolio auf einen Klick zu ermitteln. Die Berichtsergebnisse erlauben zudem direkt an die jeweilige Stelle im Projekt zu springen und dort Folgeaktionen wie Jora-Tasks an die jeweiligen Projekte auszulösen.
Improvements
- Branding auf TrustSource umgestellt -von jetzt ab ist auch TrustSource drin! Nicht nur die Optik (Logo etc.) ist auf TrustSource ungestellt, auch die URLs. Die alten URLs sind noch verfügbar, jedoch empfeheln wir, auf die neuen umzustellen. Das sind anstelle ecs-app.eacg.de nun https://app.trustsource.io für die Anwendung, https://www.trustsource.io für die Webseite und https://support.trustsource.io für den Zugang zum Support.
- Vorschau für Mengenimport bei Benutzern - Auf vielfachen Wunsch wurde der Import von Mengendaten für Benutzer vereinfacht. Es ist nun möglich, das CSV mehrfach zu laden und die Ergebnisse im Vorfeld zu sehen, sodass einzelne Zeilen vor dem effektiven Import noch einmal überarbeitet werden können.
- Jira -Status-Bericht - Der Status-Bericht für Jira-Tickets zeigt jetzt den Status der Tickets schöner an und erlaubt es auch projekctspezifsch uz sortieren.