
Open Source Compliance im Kontext von CI/CD
In den letzte Jahren hat sich Continuous Integration und Deployment (CI/CD)- die ständige Integration von Änderungen, deren automatisiertes Testen und Ausbringen – als Best Practise etabliert. Die gesteigerte Qualität und die Produktivitätsverbesserungen, die sich hierdurch erzielen lassen, sind enorm und sollten daher von jedem Entwicklungsteam angestrebt werden. Gleichzeitig wächst jedoch auch die Herausforderung im Bereich Open Source eine solide Dokumentation und rechtliche Compliance herzustellen.
Durch das kontinuierlich neue Bauen von Lösungen kann sich auch kontinuierlich die Zusammensetzung der Lösung ändern. Da der Anteil an Dritt-Software (OpenSource-Komponenten) stetig zunimmt, wird mit dem neuen Bau auch die Wahrscheinlichkeit größer, dass sich die Zusammensetzung der automatisch hinzugezogenen Dritt-Software ändert. Das Upgrade der Komponente X von Version 1.5.7 auf 1.5.8 kann bereits neue Lizenzverpflichtungen auslösen.
Leider kann eine strikte Versionskontrolle alleine diese Problematik nicht auflösen, da immer wieder das Schließen von identifizierten Schwachstellen (Vulnerabilities) und anderen Fehlerbehebungen Versions-Upgrades in allen Ebenen erforderlich machen wird. Daher stellt sich die Frage, wie sich die Compliance (1) auch in diesem dynamischen Kontext sicherstellen lässt.
Branching-Konzept als Lösungsbaustein
Um diese Frage zu beantworten, ist es erforderlich, sich zunächst mit dem Prozedere des Entwicklungsteams vertraut zu machen. Leider lässt sich immer wieder feststellen, dass es keine generell einheitlich definierte Vorgehensweise gibt. Dabei ist die Branching-Strategie des Entwicklungsteams essentiell für den richtigen Ansatzpunkt einer Open Source Compliance.
Mit Git-Flow (2), Github-Flow (3) und Gitlab-Flow (4) stehen drei anerkannte, aber zunächst unterschiedlich anmutende Handlungsanweisungen zur Verfügung. Die Varianten unterscheiden sich jedoch weniger, als es auf den ersten Blick erscheint.
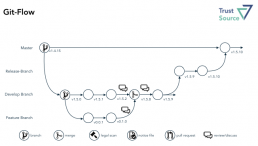
Im Git-Flow bleibt der Master unantastbar die Version, die sich auch im Produktivsystem findet. Hierdurch verspricht man sich, ein einfaches Rollback auf eine ältere Version, sollte das Deployment 2 PROD einer neuen Version fehlschlagen. Ausgehend von dem Develop-Branch werden einzelne Feature-Branches erzeugt und jeweils wieder auf den Develop-Branch zusammengeführt, um das parallele Entwickeln durch mehrere „Feature“-Teams an dem Develop-Objekt zuzulassen. Atlassian ergänzt in der Beschreibung zudem noch den Umgang mit Hot-Fixes und Releases.
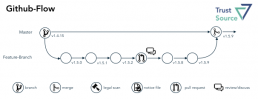
Wesentlich einfacher erscheint der Github-Flow. Einen Teil der Vereinfachung erfährt das Modell jedoch aufgrund der Verlagerung des Masters auf die Rolle des (im Git-Flow) Develop-Branch. Das vereinfacht das Verständnis, da die meisten Werkzeuge #master als Default-Branch verwenden und somit der Entwickler im Default auf dem richtigen Branch arbeitet. Unbeantwortet bleiben im GitHub-Flow jedoch die Fragen nach dem Merge in umfangreicheren Projekten, die sich aus mehreren Modulen zusammensetzen. Damit ist man dann schnell wieder bei einem Release-Branch, wie ihn der Git-Flow kennt.
GitLab hat dies in seiner Flow-Darstellung noch einmal aufgegriffen und explizite Umgebungs-Branches eingeführt, bspw. PROD, PRE-PROD, die solche umgebungspezifischen Assemblies abbilden. Die Bedeutung solcher Varianten sollte jedoch dank dynamischer, bzw umgebungsspezifischer Container-Konfiguration sukzessive abnehmen.
Inwiefern sich das als geeignet erweist, mag nur der jeweilige Projektkontext bewerten. Aus unserer Erfahrung ist ein Failback im Kontext eines Zero-Downtime-Deployments eher weniger ein Thema, das irgendwelche Repositories betrifft. Man würde für ein Rollback sicher auch nicht auf das Soruce-Repository zurückgreifen wollen, sondern lieber die bereits gefertigten Artefakte aus einem Binary-Repository holen. Daher empfehlen wir den Verzicht auf den Git-Flow-„Master“ zugunsten eines „DEV-Masters“ im Sinne des GitHub-Flows.
Die Entscheidung, ob man noch unterschiedliche „Release“-Versionen aufhebt, ergibt sich dann aus der Deployment-Philosophie bzw. dem Geschäftsszenario. Im SaaS-Kontext ist die Dringlichkeit für Release-Branches eher geringer. Wird Software hingegen verteilt, bspw. auf Geräte, die nicht beliebig für Updates zur Verfügung stehen, ist das ein essentieller Schritt für die nachhaltige Wartung. Auf jeden Fall empfehlen wir unabhängig vom gewählten Flow eindringlich die Nutzung von Binary-Repositories, um das ewige Neubauen der Artefakte nach erfolgreichem Test und Dokumentation weitgehend zu unterbinden.
Unabhängig vom gewählten Flow emfpehlen wir stets die Nutzung von Binary-Repositories
Umgang mit Multi-Modul-Projekten
Unbeleuchtet bei all diesen Themen bleibt die Frage nach den „Multi-Modul-Projekten“. Zwar werden diese durch Modularisierungstrends wie Micro-Service-Architekturen mit der Zeit weniger werden, jedoch lässt sich nicht alles endlos teilen und nicht alle Commons lassen sich stets auflösen.
Die Frage nach der richtigen Granularität des Repository-Schnitts wird fall-, bzw. projektspezifische zu beantworten sein. Daher wird es um so wichtiger, auf Seiten der Composistion Analysis ein System zu haben, das hier vollkommene Flexibilität bietet. Wir haben TrustSource daher so konzipiert, dass es beliebige Granularitäten unterstützt. Dazu kennt es die Konstrukte „Projekt“, „Modul“ und „Komponente“.
Die Idee des Projektes ist es, ein Entwicklungsvorhaben zu klammern. Es bildet den Container, in den alles projektspezifische reinkommt: Rahmenbedingungen, allgemeine Berechtigungen, alle zugehörigen Artefakte, Infrastrukturelemente etc.
Das TrustSource-Projekt ist nur eine Klammer für eine Menge an Delivery-Artefakten.
Die Module bilden entweder einzelne Deployment- oder Build-Artefakte. Dabei kann ein Modul entweder das Ergebnis eines Builds oder eine eigenständige Drittkomponente sein. Als Build versteht sich in dem Kontext alles, was im Zuge der Eigenentwicklung gebaut wird. Das kann wiederum ein einzelnes Artefakt oder ein Multi-Komponenten Projekt (bspw. EAR) sein.
Die einzelnen Komponenten, die — auch transitiv — zum Bauen eines Moduls angezogen werden, löst der der Scanner während des Bauens auf und überträgt die Stückliste an TrustSource (s. nebenstehende Grafik). Dabei kann das /SCAN-API, welches die Information entgegennimmt, auch Informationen zu „Branch“ und „Tag“ aufnehmen. Dies hilft später, die Eingaben wiederzufinden.
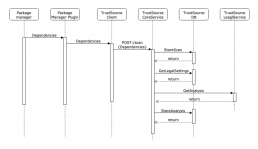
Zudem unterstützt TrustSource die Verwaltung von Drittprodukten. Das können Komponenten sein, die nicht beim Bauen auftauchen, wie ein MySQL- oder JBoss-Server, eine Bild-Datei (Ressourcen) oder eine gekaufte Library. Diese lassen sich über die Mechanismen Infrastruktur Management (für Open Source-Komponenten) oder COTS-Management (für kommerzielle 3rd Party) verwalten und organisieren und einem Projekt manuell als eigenständige Module hinzufügen.
Das Modul ist also die Klammer der Informationen für ein Build-Artefakt. Es enthält den Teil der rechtlichen Informationen, die modulspezifisch sind, die Architekturposition, Zugriffsrechte etc.. Soweit Letztere nicht für das jeweilige Modul explizit geändert werden, sind sie bereits durch das übergeordnete Projekt gesetzt.
Beispiel
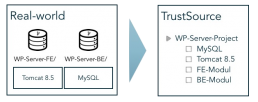
Nachstehendes Bild zeigt die Struktur eines Workplace-Servers. Dieser besteht aus einem Frontend- und einem Backend-Modul, die beide in einem Projekt-Repository abgelegt sind. Der Workplace-Server benötigt zudem einen Tomcat 8.5 und einen MySQL-Server als Ausführungsinfrastruktur. Diese beiden Module sind als Infrastruktur-Module hinzugefügt. Sie werden nicht gebaut, sind aber Bestandteil der Anwendung und entsprechend in die Compliance-Betrachtung einzubeziehen.
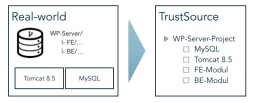
Dabei ist es egal, ob die Frontend und Backend-Module aus dem gleichen Repository kommen oder aus unterschiedlichen. Das Ergebnis in TrustSource sieht unverändert aus.
Interessant wird jetzt die Release-Strategie. Liegt die Release-Version auf Anwendungs-Ebene (äußeres Kästchen), wird es also immer nur eine Version der Anwendung geben, sind alle Module jeweils nachzuziehen, um mit der Release-Version Schritt zu halten, oder es muss eine Kombination unterschiedlicher Sub-Release zu dem Gesamt-Release geben. Zum Beispiel würde sich die Version 2.0.0 der Anwendung aus den Versionen Tomcat 8.5, MySQL 5.1 und Frontend 2.0.5 sowie Backend 1.5.16 konstituieren.
Für diesen Fall gibt es seitens des Repository nur dann eine Entsprechung, wenn ein GitLab-artiges Repository für die Produktionsumgebung gepflegt wird, in welches die unterschiedlichen Stände eingebracht werden. Es wird in diesem Kontext erforderlich – wie in allen Multi-Komponenten-on-premises-Projekten ohnehin – einen Release-Brach aufzusetzen, um das Zusammenspiel von Frontend und Backend zu testen, bevor sie ausgebracht werden.
Einbindung der Compliance in den CI/CD-Flow
Als Scan wird das Ergebnis des Scanners bezeichnet, welcher lokal oder auf dem Build-Server ausgeführt wird. Er erzeugt die Struktur inklusive Abhängigkeiten und überträgt diesen „Scan“ mit Hilfe des gleichnamigen API an TrustSource. Dort übernimmt der Scan-Processor den Scan, gleicht die gefundenen Informationen mit der internen Komponentendatenbank ab und bindet den Input an das zugehörige Modul.
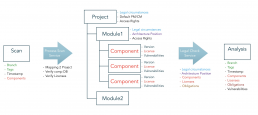
Hierdurch entsteht der Kontext. Das Projekt und das Modul halten Rahmenbedingungen, welche für das Projekt bzw. Modul gelten sollen. Das betrifft die Kommerzialisierung sowie andere relevante Aspekte, wie bspw. den Schutzbedarf von IP. Diese Information zusammen mit den Komponenten und Lizenz-Informationen werden dann an den Legal-Check-Service übergeben, welcher die sich aus den Rahmenbedingungen und den Lizenzen ergebenden Verpflichtungen (Obligations) ableitet.
In der Detail-Ansicht findet der Benutzer letztendlich die Summe aller dieser Schritte, das Analyse-Ergebnis. Um eine engere Bindung zwischen dem Quellcode und der Management-Welt herzustellen, stellt TrustSource die Felder „branch“ und „tag“ in dem API /SCAN bereit. Somit lassen sich mehrere Zustände eines Moduls problemlos auseinanderhalten.

Wichtig für das Verständnis der weiteren Schritte ist es, zu verstehen, dass der SCAN die Struktur des Quellcodes wiedergibt. Dieser ist zunächst unbewertet. Erst das in der Detail-Ansicht dargestellte Analyse-Ergebnis ist eine Interpretation vor dem Hintergrund der zum Analysezeitpunkt gültigen Rahmenbedingungen! Daher gilt:
- Jeder Upload erzeugt einen neuen SCAN
- Ein SCAN wird in der Regel einem MODUL zugeordnet, wodurch er seine Rahmeninformationen erhält
- Jedes MODUL gehört zu genau einem PROJEKT – bis auf das systemeigene Sammelmodul „Unassigned“, hier findet sich alles, was nicht automatisch zugeordnet werden kann
- Jeder SCAN erzeugt mindestens ein ANALYSEERGEBNIS (automatisiert)
- Ein MODUL kann beliebig viele ANALYSEERGEBNISSE haben
- Ein SCAN kann beliebig oft an TrustSource übertragen werden, die Zuordnung zu einem MODUL lässt sich bei der Übertragung festlegen
Scans zuordnen
Aus dieser Menge an Fakten lassen sich beliebige Szenarien zusammenstellen. So kann jeder Entwickler an das Ziel-Modul seine Scans schicken und diese mit Hilfe von Branches und Tags differenzieren. Um eine direkte Zuordnung zwischen Code und Analyse-Information herzustellen, könnte man die Commit-ID als Tag anlegen.
Will ein Entwickler seine Experimente nicht in dem allgemeinen und für das gesamte Projekt ersichtlichen Modul einbringen, kann er eine eigene Projekt/Modul-Konstellation anlegen und die rechtlichen Einstellungen aus dem ursprünglichen Projekt kopieren. Somit kann er in seiner Version herumprobieren, ohne den allgemeinen Stack zu belasten.
Andererseits kann es auch sinnvoll sein, sämtliche Branches in dem Modul zu halten, um einen guten Überblick über die Veränderungen zu erhalten. Mit Hilfe des Branch-Selektors im User-Interface lässt sich jede Version direkt auswählen und einsehen.
Approvals einordnen
Doch was ist nun ein Approval? Das Approval ist ein administrativer Schritt, der es dem Projektleiter und den Entwicklern ermöglichen soll, sich von der Domänen-fremden Aufgabe der rechtlichen Begutachtung ihrer Leistung frei zu zeichnen. Hierzu bereitet TrustSource alle Unterlagen für eine Prüfung auf und stellt diese einem rechtlich gebildeten – im TrustSource-Sprech, dem Compliance Manager – zur Verfügung. Dieser muss dann nur noch die Vollständigkeit bzw. Eignung prüfen, wobei ihn TrustSource auch unterstützt, und kann dann eine Freigabe erteilen.
Die Approvals finden idealerweise nicht nach jedem Scan statt, sondern nur vor Merge-Schritten. Dabei sind der Umfang und die Häufigkeit organisationsspezifisch festzulegen. Im Regelfall erfolgt ein Merge in einem vergleichbaren Kontext wie in nachstehender Abbildung gezeigt. Dabei ist es unerheblich, ob es sich um einen Pull-request oder einen richtigen Merge handelt. Ist der zu integrierende Inhalt von einem für seinen Umfang vollständigen Notice-File versehen, kann dieser Inhalt auch in den zusammengeführten Baum übernommen werden und hält die Gesamtdokumentation somit vollständig.
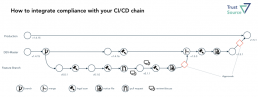
Die obige Darstellung ist um die Scans und die Generierung der Notice Files erweitert. Wir empfehlen, die Notice-Files als Bestandteil einer Definition of Done aufzunehmen. TrustSource verfügt über einen Notice-File Generator. Dieser sammelt sämtliche vorhandenen Informationen und zeigt, welche Informationen noch fehlen, um den Notice-File zu vervollständigen.
Wir empfehlen, vor jedem Merge einen Notice-File zu erzeugen. So ist jeweils nur das Delta zum bisherigen Bestand zu ergänzen
Alle ergänzten Daten stehen ab dem Zeitpunkt der Ergänzung allen Projekten zur Verfügung. Somit sind allgemeine Informationen nur einmal zu erfassen. Das reduziert die Clearing-Aufwände erheblich
Die tatsächliche Gestaltung der Abläufe wird in jedem Unternehmen, vermutlich sogar in jedem Projekt, etwas anders verlaufen. Eine allgemeingültige Darstellung zu verordnen, ist daher weder sinnvoll, noch empfehlenswert. Die Wahrscheinlichkeit, dass sie mehr schadet als nutzt, ist einfach zu hoch. Auch kann es sinnvoll sein, das Vorgehen im Zeitablauf anzupassen. Wird ein Modul nur noch angepasst, ist ein weniger differenziertes Vorgehen empfehlenswert, als wenn mehrere Teams gleichzeitig an den Elementen arbeiten. Wird jedoch vor jedem Merge ein Notice-File erzeugt, ist jeweils nur as Delta zum bereits bestehenden Notice-File zu ergänzen und sowohl der Arbeitsaufwand als auch die spätere Herausforderung für die Compliance-Prüfung halten sich in Grenzen.
Literaturhinweise:
(1) Welche Herausforderungen die Compliance beantworten muss, findet sich in dem Artikel „Aktuelle Herausforderungen der Open Source Compliance“.
(2) Git-Flow: https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
(3) GitHub-Flow: https://guides.github.com/introduction/flow/
(4) GitLab-Flow: https://about.gitlab.com/2014/09/29/gitlab-flow/
(5) s. https://github.com/dotnet/corefx/