Open Source Compliance in the context of containers
Modern software development, especially micro-service architectures, is hardly imaginable without container technologies such as docker. The promises of ease and Flexibility through containers prove true. But what does this flexibility mean for open source compliance?
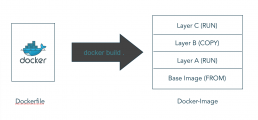
It’s wonderful: Just take an image (FROM instruction) from the Docker hub with e.g. a Linux Alpine – a very lightweight Linux distribution – as a base, then add some source files from your own repository (COPY) and build the target application with Maven (RUN). Quickly add a web server with apk add package (RUN) and adding some configuration (another COPY). The Java service is ready for delivery. Thanks to Docker!
It seems to be very little: A Docker file with 6-7 lines, plus a handful of own classes, maybe 300-500 lines of code. Nevertheless, in total, half a million lines of code are created. 99.9% of it is open source, additionally pulled from the net when building the image. Irrespective of any security concerns, this is how many of the services used today are created, especially in the context of current micro-service architectures.
A considerable share of almost all services is based on Open Source
This description is not intended to diminish the performance of service developers, nor is it generally applicable. However, it shows roughly the relation in which open source has spread in today’s software development. A significant part of the efficiency gain in software production is based on the free availability of infrastructure solutions as open source.
Irrespective of this, however, new challenges also arise with this clout. In the commercial environment in particular, the use of open source must be well documented, not only for security reasons. There are also legal reasons:
Whenever an author’s work is used by a third party, the user must secure the rights of use. This is done by an agreement – even tacitly – between the author (copyright holder) and the user. This is usually done by the author placing his code under a “license”. In the context of Open Source, these licenses usually grant the rights for commercial or even scientific use, modification and distribution open source or binary, etc.. There are hundreds of these licenses, some more open, some more restrictive, see the OSI license list or the official SPDX list.
Know the conditions of Open Source
Very important for the users of Open Source is, however, that many of the comparatively open licenses also impose conditions for their validity! If these conditions are not fulfilled, the right of use is void!
The following excerpt from the certainly well-known Apache 2.0 license, for example, clearly binds the right of distribution to the compliance with additional conditions. These conditions include, among others, the provision of the license text, the naming of authors or the retention of copyright information in the source code. In addition, these must be explained in a “notice file” if necessary. If any changes have been made to the software, these must also be reported. If even one of these conditions is not fulfilled, the right to distribute the software expires!
Containers add a special aspect to this already demanding list of requirements. With the help of containers, it is possible to deliver essential parts of the runtime environment preconfigured. This extends the scope of the delivery considerably. If a Zip, EAR or WAR file with its own source code has been delivered so far, a Linux with pre-installed Tomcat, Wildfly or other Open Source components can be delivered directly ready for use in the container.
If not only the docker file – i.e. the recipe for the construction – is delivered, but the finished image, all infrastructure components become part of the delivery. Depending on the type of license, this can have different consequences, especially in the area of documentation, but also with regard to intellectual property. In any case, it would be critical if one of the license conditions is not fulfilled. Unauthorised commercial marketing is no longer a trivial offence.
The majority of open source licenses require at least the naming of the author, if not the provision of the license together with the delivered solution. However, if you look at the images on Docker-Hub, you will find neither bills of material nor corresponding metadata, let alone license texts. Rarely enough, there is at least a hint or link to the terms and conditions on the Docker file/image.
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
-
You must give any other recipients of the Work or Derivative Works a copy of this License; and
-
You must cause any modified files to carry prominent notices stating that You changed the files; and
-
You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
-
If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
Accepting documentation as a challenge
Woe betide the person who is now to carry out the compliance documentation for a docked product enriched across several value creation stages / partners! As described above, most different sources for the origin of the image finally used come into question. Especially critical are the manually added files. These can contain everything imaginable and elude virtually any form of analysis.
Furthermore, the author of an image has the possibility to copy something into the image from public or private sources, to load source code, to install and execute packages or software or even to build it. The latter is also possible with the help of package managers, which in turn resolve and obtain the necessary dependencies. In short: a docker image offers its author in each layer the opportunity to do all the dirty things he could do on a server as well.
Tools and support
Fortunately, there are several OpenSource tools that can help here. Not all of them were created for this purpose, but some of them can be used. There is tern on the one hand, and Clair on the other.
Tern is developed by a small team at vmware to decompose docker images and collect the license information of the components contained in them. The focus is on analysis for legal purposes.
Clair was created with the focus on vulnerability analysis and has less focus on the legal issue. However, Clair also indexes the components of a container and could therefore serve as a supplier of BOM information. However, if only the legal aspect is in focus, Clair would be shooting at sparrows with cannons (see below).
tern
Tern can perform its analysis on the basis of a Docker file as well as a Docker image. To do this, tern uses Docker, as well as the Linux “find” command in conjunction with the extended attributes of the Linux file system. In the newer Linux distributions the required attr-library is already available, in older Linux distributions it may have to be installed later.
Since tern activates the find command with the help of a simple bash script and analyzes the files on mounted host volumes, the Docker version of tern is unfortunately also currently not executable on Mac or Windows. However, it runs well on a Linux system. tern is developed with Python 3 and can also be installed via PIP.
As a result, tern prints a list of the components it has found in each layer of the image (see example).
A docker image creates a docker container. It is, so to speak, the building regulation according to which the Docker demon assembles the container. You can imagine the container construction analogous to a 3D print. Each command line of the docker file creates its own layer. These layers are separated by namespaces and therefore more independent than on a real system.
Thus an existing image can be loaded with the help of the FROM command. It comes with everything that its author gave it. What this is can only be determined exactly if This is one of the reasons why you should only get images from trustworthy sources or preferably build them from scratch!
Images should always come from trustworthy sources or be built from scratch!
Furthermore, the author of an image has the possibility to copy something into the image from public or private sources, to load source code, to install and execute packages or software or even to build it. The latter is also possible with the help of package managers, which in turn resolve and obtain the necessary dependencies. In short: a docker image offers its author in each layer the opportunity to do all the dirty things he could do on a server as well.
------------------------------------------------
Layer: 9a78064319:
info: Found 'Ubuntu 18.04.4 LTS' in /etc/os-release.
info: Layer created by commands: /bin/sh -c #(nop) ADD file:91a750fb184711fde03c9172f41e8a907ccbb1bfb904c2c3f4ef595fcddbc3a9 in /
info: Retrieved by invoking listing in command_lib/base.yml
Packages found in Layer: adduser-3.116ubuntu1, apt-1.6.12, base-files-10.1ubuntu2.8, base-passwd-3.5.44, bash-4.4.18-2ubuntu1.2, bsdutils-1:2.31.1-0.4ubuntu3.5, bzip2-1.0.6-8.1ubuntu0.2, coreutils-8.28-1ubuntu1, dash-0.5.8-2.10, debconf-1.5.66ubuntu1, debianutils-4.8.4, diffutils-1:3.6-1, (…) , zlib1g-1:1.2.11.dfsg-0ubuntu2
Licenses found in Layer: None
------------------------------------------------
Layer: dd59018c47:
(…)
If things go well, tern also supplies meta data such as licenses for the identified packages. The tool still has some difficulties with the analysis of chained commands (&&) in the docker file and – inevitably – the processing of the contents of COPY statements. To overcome the latter, the tern team has now created a way to integrate other tools – such as Scancode ((https://github.com/nexB/scancode-toolkit)) from nexB.
In addition, we are currently working on extending tern with an interface to TrustSource so that the results of the analysis can be transferred directly to TrustSOurce for further processing. The image would be a separate project, the layers found would be interpreted as TrustSource modules and the components found within a layer would be interpreted as components. This would make it possible to combine the found components with the TrustSource metadata and vulnerability information, thus integrating the container into a compliance process and automating the documentation as far as possible.
Clair
On the other hand there is the Clair, originally developed by Quay.io – now part of RedHat via coreos – in go-lang. As described above, Clair focuses on the identification of vulnerabilities in Docker Images. The heart of Clair is a database which is continuously fed with vulnerability information.
This database can be accessed via an API and thus can be integrated with the container registry used in your own project. Thus, scans do not have to be done manually, but can be integrated into the CI/CD chain after image creation.
In the course of the scan, a parts list of the image is generated – analogous to tern’s procedure – and transferred to Clair. There the components found are then compared with the collected vulnerability information. If necessary, Clair can trigger certain notifications to draw attention to identified vulnerabilities.
In principle, this is a sensible structure. Especially if there are a large number of image producers and buyers, it is highly recommended to explicitly check the images again for vulnerabilities.
However, the use of image-specific whitelists, as envisaged by Clair, is quite critical in this context, as vulnerability 1 is not dangerous in use case A and can therefore be placed on the whitelist, but could be dangerous in context B. Image-specific whitelists would therefore be rather counterproductive. As in our TrustSource solution, the whitelists must be context-specific.
Another limitation of Clair is the time of the scan. This only takes place after the image has been built and transferred to the repository. Actually, no image with vulnerabilities should be transferred to a repository! Errors should already be found in the CI/CD process and the image should not even be built, let alone stored.
For this reason Armin Coralic (@acoralic) has extracted a scanner version based on the work of the coreOS team, which can be integrated into the CI/CD process, preferring work, so to speak (see GitHub). In its current form, however, this version only displays the weaknesses found, not the entire structure, although it must be able to detect them. It is therefore advisable to output the structure list available in Clair directly. This would require appropriate adjustments to the Clair project.
TrustSource Platform
We generally recommend that all checks be drawn as far forward as possible in the software development process. This enables the developer to inquire about the status of a library or component or its possible vulnerabilities at the time of its installation. Should the component prove to be too old, too faulty or legally unsuitable, the developer saves time and unnecessary integration work.
TrustSource uses the Check-API for this purpose. This enables developers to perform these checks from the command line. The TrustSource scanners already mentioned above (see here) can also cover this task automatically in the CI/CD pipeline for a large number of languages. This is already _after_ integration, but still _before_ further processing by others.
TrustSource can also integrate runtime components as infrastructure modules in the respective project context and enrich them with meta data by means of crawlers that run independently in the background. This collection of information reduces the documentation effort and, by concentrating the information in one place, allows you to automatically monitor appropriately released compositions throughout the life cycle. Detailed information on the individual TrustSource services and how they support compliance tasks can be found at https://www.trustsource.io.
Conclusion
The preceding explanations show that by using container technologies such as Docker, in addition to the pure source code runtime components can quickly be included in the “distribution”. This increases the urgency of a precise, systematic software composition analysis. Although there are a handful of Open Source tools that make it possible to approach this challenge as well, they are still quite isolated and only little integrated into a comprehensive, life cycle-oriented process.
With TrustSource, EACG offers a process-oriented documentation support that is designed for the life cycle of an application and integrates many tools for the different tasks. TrustSource itself is also available as open source in a community edition for Inhouse use, but also might be subscribed to as SaaS.
EACG also offers consulting in the area of Open Source strategy as well as in the design of Open Source governance and compliance processes. We develop the TrustSource solution, which is also available as open source, and thus help companies to securely exploit the advantages of open source for their own value creation and to avert the associated risks.