TrustSource v2.0 to come!
TrustSource 2.0 comes with new look & feel
We are proud to announce availability of the upcoming v2.0 of TrustSource by May 7th.
Since the list of features has become a bit crowded over the last few versions, we have arranged the navigation area into groups. These are organized according to the phases of value creation, which helps to find your way more quickly: Scanners in the Inbound group, Vulnerability Information and Project Management Tasks goes into Internal, or Notice File Generation you will find in Outbound.
More focus in work
Furthermore, we help our customers to focus. Especially in larger organizations with extensive project portfolios, it becomes important to move quickly and focus. With the help of the “Pin to Dashboard” function, it is now possible to pin projects directly to the dashboard, enabling direct link with just a few clicks. Also included in this segment is the ability to tag projects and modules. Table views can be filtered with the help of tags, which quickly provides more visibility. In later expansion stages, the tags will also be usable in the reports and other overviews.
Vulnerability Lake
To simplify your daily work, we have included a complete replica of the NVD data. Updated every two hours you can now browse through the CVEs, research by organisation, product and versions (CPEs) from within TrustSource or through our API. It is our intention to grow the pool of data and make this valuable knowledge available at your fingertips.
New import API for CycloneDX SBOMs
We have also taken into account the developments on the market and included the CycloneDX standard, which is establishing itself more and more quickly. It is now possible to import CycloneDX documents. This means that all CycloneDX-compatible scanners can also be used to work with TrustSource. The documents only have to be transferred to the new API /import/scan/cyclonedx.

Improvements
In addition to that, we also will introduce a row of improvements
- It will now possible to jump back and forth between the scan – the raw data introduced to TrustSource by any scanner or the CycloneDX SBOM upload – and the analysed dependency view. This will help to understand the dependency hierarchy.
- We have improved the speed of loading the analysis selector. Daily scanned but never changed projects had a tendency to produce a heavy latency.
- DeepLinks from DeepScan results view into the repository are now also supported for specific branches
Fixes
The following fixes will be provided:
- Deletion of license alias in a non sequential order will not produce empty aliases anymore
- Preventing an internal error when module or component names were extraordinarily long during Scans
- Date representation in Safari sometimes did not work correctly
- Some adjustments to component crawlers and the storage of results will reduce the amount of buggy data
How to convince your Management of the importance of Open Source Compliance
How to convince Management
Often when talking to our customers from the corporate areas, we recognize a reasonable acceptance for the topic in the developers levels. There is an awareness for the “copyright”-aspects of software. On the one hand this is due to the many years of beating the drum for that topic, that most engaged developers experienced meanwhile. On the other hand it is due to many of them publishing software by themselves.
Unfortunately these experiences are moving in the background in the same way as financial aspects appear in the foreground. The more people focus on financial and commercial aspects of a product or service, the less room for respect of creative freedom seems to exist. This does not mean, that managers tend to underestimate the quality of work they receive in open source products nor shall it put the league of managers in the corner of ignorant work bots. But whenever you are facing deadlines for delivery and/or have to align budget constrains with a competitive feature list, open source compliance remains the 2nd priority to look for.
Not looking for open source compliance might be a bad mistake…
This might be a bad mistake! Open Source Compliance is not an option, it is a must! The key aspect of open source compliance is the generation of a “Software Bill of Materials”. The closer your solution is to a piece of hardware, the more it will be relevant as it is most likely that the software will be distributed with this piece of hardware. Missing out on compliance – even by accident – might be seen a as criminal act. Not addressing compliance aspects in a commercial organisation is a sort of fraud.
…especially due to the fact, that it can be heavily automated!
Thus management is well suited taking care of compliance. Especially due to the fact, that it meanwhile can be heavily automated. Integrate the generation of SBOMs with your CI/CD chain, derive the context of your solution and resolve the resulting requirements can be fully automated at almost no costs by using free and open source tooling. Learn about available options in the article on the “Open Source Compliance Tooling Capability Model”.
However, if you will have to convince your management to care for more compliance or want to learn on how to setup and establish a compliance program, download the slides attached to this post or reach out to one of our consultants.

How TrustSource protects against dependency confusion attacks
What has happened?
Security researchers have managed to gain access to various high-security networks with the help of a dependency confusion attack. With this attack, they managed to send protected information and data from within the affected networks to the outside. However, depending on the attack scenario, other activities would also be imaginable. Once behind the defense lines, the damage scenario can be freely chosen.
How was the attack executed?
The security researchers got the idea when they found names of private packages in the published open source tools of the companies (Apple, Adobe, etc.)
Companies often use open source and supplement certain functionalities or graphical controls with their own libraries. These, in turn, are developed by only one team and made available as separate packages or libraries to other development teams. This is efficient and convenient because the broad set of development teams does not have to worry about it, yet the look-and-feel remains consistent across different applications or services.
If the companies now play software back to the community and the references to such “private” packages are not removed from the source code, the release will carry the name of these packages outside. This in itself is not that dangerous. It only becomes interesting if the information is exploited for a dependency attack (see next page).
How could you protect yourself from this to happen?
- Component naming:
If the internal component names follow a naming scheme, such asORG.COPMANY.UNIT.UITOOLS, it becomes much more difficult for third parties to create corresponding names in the package managers without causing a stir.ORG.COPMANY.UNIT.UITOOLSis more noticeable than the 100th version ofUITOOLS. - Configuration of packet manager proxies:
To be successful in the attack, the local distribution mechanisms must be outwitted. It should be ensured that no updates are pulled from outside for certain package types, e.g. with the help of the name identifier or a simple blacklist. - Version control:
With the help of a version history, it quickly becomes possible to determine which versions are in use. A jump from 1.2.3 to 69.1.0 can be discovered quickly or is noticeable.
What is a dependency confusion?
Modern package systems use package managers, especially to manage the ever-growing number of open source components. Each build specification therefore contains a list of the components to be included. In Java this is the POM.XML file, in Node.JS (JavaScript) it is the PACKAGES.JSON.
In this file the components and the minimum requirements to the components, the version numbers are indicated. Since many components change frequently, the requirements often contain not only the exact version number, e.g. 1.2.3, but a note like ^1.2.3, which means something like: “Give me at least 1.2.3 or newer.” . If the maintainer of the component updates to e.g. 1.2.4 (new patch) or 1.3.0 (new feature), the own solution would be able to profit from the innovations with the help of the formulation during the next build.
If a malicious actor now posts a newer version in a package manager, for example a 12.1.0, he can be relatively sure that this version would be provided by the package management for the context described above.
If the project now builds a new version, the malicious code would be pulled from outside, integrated into a QA system, and deployed there. Depending on the damage scenario chosen, a lot can be done with this.
You want to manage vulnerability protection along the complete lifecycle of your product?
TrustSource can help to protect you!
If you use TrustSource, it will know the current versions of your modules and solutions, as well as publicly available components. Sudden version jumps of publicly available components are detected by our systems and reported to our support team for review. Critical developments are reported back to the projects.
If you are already using TrustSource, you are probably familiar with the concept of “linked modules”, the integration of releases of your own software. If versions appear here that were previously unknown, this also leads to a report to the respective project manager. In this way, you can be sure to notice corresponding developments quickly.
TrustSource @ FOSDEM 2021
TrustSource @ FOSDEM 2021
we are looking forward to the presentations of @Jan Thielscher & @Grigory Markin at FOSDEM 2021.
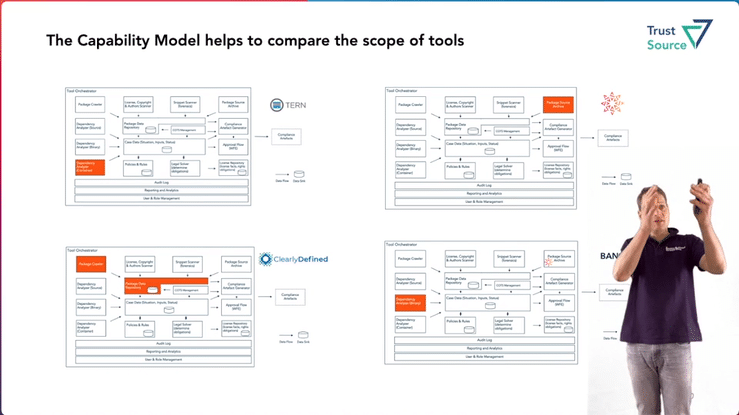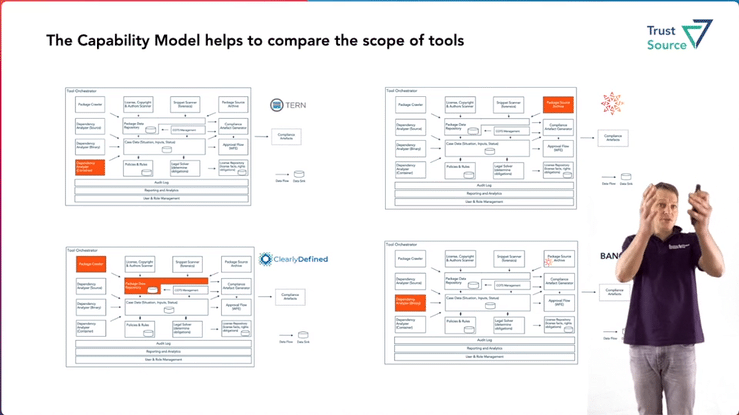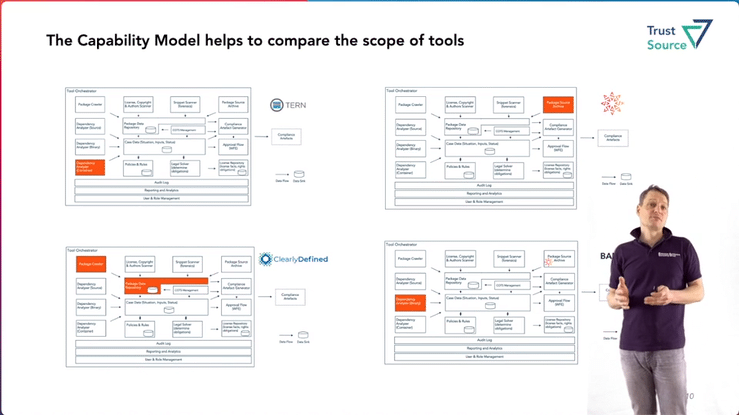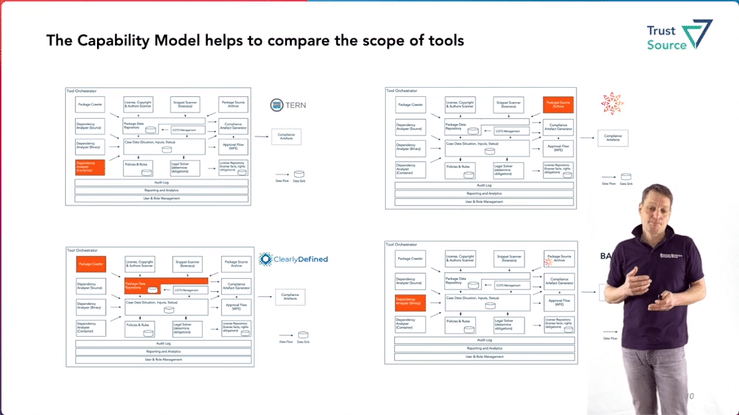
Open Source Compliance Tooling – Capability Reference Architecture
Jan will present the Open Source Tooling Workgroup‘s reference model in the OpenChain Dev-Room , which outlines domain-specific capabilities and their interrelationships. The model has been created over the last two years by members of the workgroup and is intended to provide an overview of the required tasks that will be needed in the context of open source compliance. It is also useful for mapping the different tools or being clear about what functionality they cover. See the complete video here.
During the talk Jan will also try to motivate tool vendors to map their tools against the model.
In a second talk, Grigory Markin will present the TrustSource DeepScan open source tool and the free online service DeepScan of the same name in the Dev-Room Software Composition. This solution has been developed to support open source users in identifying the effective licenses and attribution information (license & copyright) :
TrustSource DeepScan – How to effectively excavate effective licenses
In this 15 minute talk, Grigory and Jan will briefly outline the challenge of “effective” licenses and discuss the various technical possibilities and challenges of automated license analysis using similarity analysis, among other things. Finally, the tool, the current state of work and the next steps will be briefly presented.
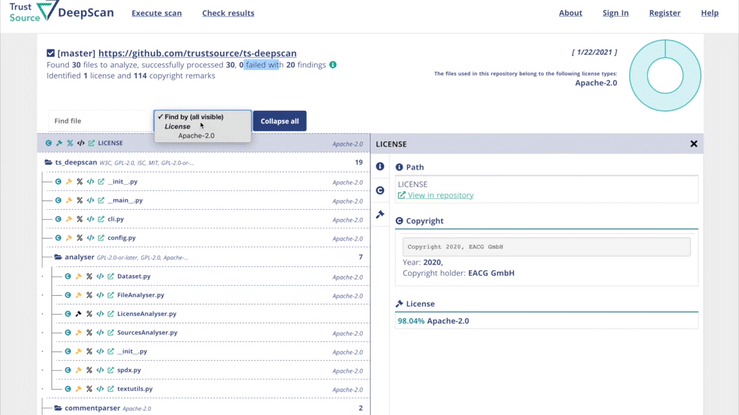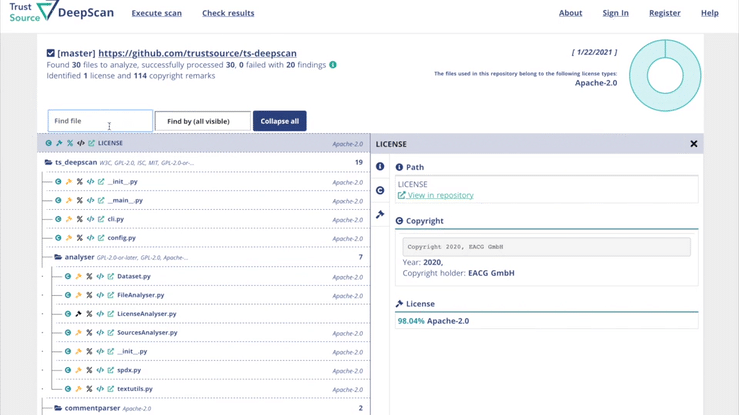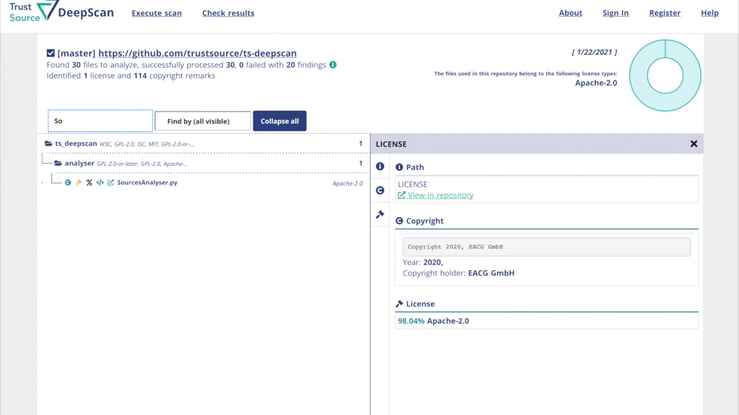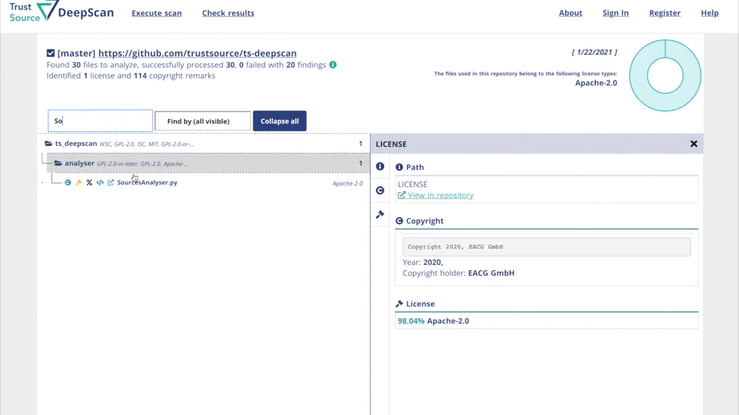
ISO 5230 - Standard on open source compliance
December 14th, 2020, the International Standardisation Organization (ISO) publicly released ISO 5230, the first standard on open source compliance (OSC). The standard is a result of several years work of a working group under the umbrella of the linux foundation. Since several years many cope source compliance experts from leading technology organisation worldwide sat together and shaped a simple, but efficient approach on how to tackle the open source compliance challenge.
The following video – a recording of the 10 min introduction to the OpenChain project Jan held Feb 6th @ this years FOSDEM – explains the core idea of the OpenChain project and introduces the core specification requirements (outline of the ISO 5230).

You think that ISO 5230 is relevant for your company? You want to learn more?
Do not hesitate to reach out for a quick chat!
OpenChain helps to build trust along the value chain by requiring certified participants to comply with specified requirements on how to arrange their open source usage and management. Since we are involved with OpenChain for several years now, we took the ideas and embedded them into TrustSource. Thus TrustSource is best suited to support the introduction as well as the ongoing compliance with ISO 5230, respectively the OpenChain requirements.
Interested to get a better understanding of how TrustSource may support your OpenChain/ISO5230 certification?
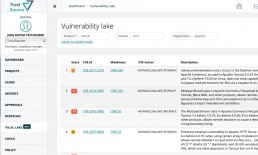
Vulnerability Lake in beta
TrustSource adds Vulnerability Lake
Due to many requests we decided to open up our internal vulnerability DB for research by developers. Starting from version 2.0 TrustSource will provide its internal “known vulnerability” database for search. There will be several searches available:
- TrustSource Vulnerability-Lake public web UI
- TrustSource Vulnerability-Lake web UI
- TrustSource Vulnerability-Lake API
The public web UI as well as the TrustSource integrated web ui provide a simple and an expert search mode. You …
TrustSource Vulnerability Lake allows simple overview of vulnerability status

TrustSource DeepScan - Catch effective open source licenses
TrustSource DeepScan - CLI, web-based or as part of service
DeepScan is an open source tool, helping you to achieve open source compliance. You may use DeepScan to scan the repositories of your solution or the components you are applying. It will identify all license and – if wanted – copyright information. This is relevant to ensure that you have the correct understanding of the rights and obligations associated with the open source components you are using.
DeepScan is available in three flavours:
While the CLI version is fully functional, it requires the user to assess the results file by himself. The CLI-version can publish its findings either in standard out or in a file using JSON. The web-based UI provides a comfortable way to watch and work with the results. The solution integrated with TrustSource allows you to amend the findings and share your data with others.
Why are effective licenses so relevant?
Everybody developing software should have an understanding about the components he is using to provide his solution due to two reasons:
- Legal compliance
- Security
Getting a grip on legal compliance
From the legal perspective, it is essential to understand what your solution consists of. Open source does not imply free goods. Just to have free access does not mean you are free from obligations. Often open source components come with a license that requires the user to comply with certain obligations. In many cases the right to use is bound to the compliance with some obligations, e.g. attributing the copyright holder.
Theoretically every component can have its own license. In practice it turns out that there are roundabout 400 licenses and a countless number of derivates that govern the usage of open source. Some are more, some are less restrictive. However, given you do not take care for the rights and obligations associated with the components you are using, you swiftly slide out of legal conformance. In the worst case official law enforcement might charge senior management of companies not effectively preventing such risk with professional fraud.
DeepScan helps to assess repositories for license indications, exposing all findings in a comfortable way. Compiled into one reult, with links into the depth of the repository allowing fast tracking and review.
Give it a try!
No installation or registration required…
Keeping track of what is used improves security
The second reason, why you better should be aware of the components inside your solution is, to learn early about issues associated with such components. Given you have the structures of your solutions scanned with TrustSource, all versions of the builds are chronologically available. trustSource checks NVD and other vulnerability boards for updates and compares incoming data with its components information. If you use – or have used – a vulnerable component, you will get a notification.
This gives you an advantage over potential malicious actors. You may inform your customers still using vulnerable versions, start working on fixes or at least help them to prevent misuse by malicious actors.
So you see, there are many reasons, why you should know what is inside your code base….
To learn more about the different DeepScan solutions we provide, see this short video introduction. This speech will be provided at FOSDEM 21 in the Software Composition Analysis DevRoom.

Module 2 - Open Source Compliance and Security

Module 2 - Achieving Compliance and Security
- Goals:
Understanding of managing compliance and security risks, operational fulfilment using TustSource -
- Contents:
Compliance & Security goals, risk management approach, handling compliance risk, handling technical risk (security, viability),
Part I: achieving compliance , practical questions (cases), TrustSource tools to achieve compliance (understanding legal settings in detail, functionality of legal engine, private licenses, black- & whitelists for components and licenses, etc.), detailed assessment of a notice file, collecting attributions, change notifications making use of DeepScan to qualify sources, quizz
Part II: managing and assessing vulnerabilities, finding further vulnerability information, limitations of vulnerability data, examples analysing vulnerability data, using vulnerability reports, assessing viability, versions-analysis, forwarding tasks/tickets, handling developer versions, muting vulnerabilities, quizz
Part III: making use of infrastructure, 3rd party & COTS, handling private and commercial licenses, using linked modules in a different context , COTS report, SOUP list, quizz, Summary and test -
- Target Groups: project Managers, compliance Managers, developers

Module 1 - Compliance basics
Module 1 - Compliance Basics
- Goals:
Create awareness for the topic, introduce basic meanings -
- Contents:
Challenge of OSC (clarify direct vs. transitive dependencies) , recent and important cases, What if not?, basic terms, grants, obligations & their consequences, limitations and the termination of grants, matching to basic license classifications, check basic understanding, sample cases, roles and their responsibilities, general compliance process, Overview of the OpenChain specification, summary & test -
- Target Groups:
developers, administrators, compliance managers, product managers, project managers, senior managers

Module 4 - Developer Guidelines
Module 4 - Developer Guidelines
- Goals:
Provide understanding of relevant Compliance goals and artefacts , provide basic understanding of TrustSource elements as well as how to use them to achieve compliance -
- Contents:
Explain basic TrustSource constructs (Scans, Analysis, Reports, project settings, etc.), explain Compliance Artefacts (BoM, Notice File, SOUP-List, Compliance Report, etc.), clarify Developers responsibilities (Compliance & Security), TrustSource Support tools (using the UI, filtering, searching, dependency graphs), manage loose coupling and modification, how to manage settings, explain legal circumstances and their impact, Project manager responsibilities (Compliance & Security), TrustSource tools (Legal Analysis, Security Analysis, Viability Analysis, VersionCheck, different Reports), Understanding the approval flow, approval Dry-Run, integrating approvals (Git-flow, Github-flow), using projects and modules to structure work, running tests, using linked modules, adding infrastructure modules, integrating COTS, qualifying external repositories, sample assessments, resolution of sample cases (making it green), summary & test -
- Target Groups:
Developer, Project Manager, Administrators, Compliance Managers -